Co To jest NoSQL?
baza danych NoSQL jest nie relacyjnym systemem zarządzania danymi, który nie wymaga stałego schematu. Unika łączenia i jest łatwy do skalowania. Głównym celem korzystania z bazy danych NoSQL jest rozproszone magazyny danych z ogromnymi potrzebami przechowywania danych. NoSQL jest używany do dużych zbiorów danych i aplikacji internetowych w czasie rzeczywistym. Na przykład firmy takie jak Twitter, Facebook i Google zbierają terabajty danych użytkowników każdego dnia.,
baza danych NoSQL oznacza „Not Only SQL” lub „Not SQL.”Choć lepszym określeniem byłoby” NoREL”, NoSQL się załapał. Carl Strozz wprowadził koncepcję NoSQL w 1998 roku.
tradycyjne RDBMS używa składni SQL do przechowywania i pobierania danych w celu uzyskania dalszych informacji. Zamiast tego system bazodanowy NoSQL obejmuje szeroką gamę technologii bazodanowych, które mogą przechowywać dane ustrukturyzowane, półstrukturalne, nieustrukturyzowane i polimorficzne., Zrozummy o NoSQL z diagramem w tym samouczku bazy danych NoSQL:
w tym samouczku NoSQL dla początkujących nauczysz się podstaw NoSQL, takich jak:
- dlaczego NoSQL?
- Krótka historia baz danych NoSQL
- funkcje NoSQL
- typy baz danych NoSQL
- narzędzia mechanizmu zapytań dla NoSQL
- czym jest twierdzenie CAP?
- konsystencja
- zalety NoSQL
dlaczego NoSQL?,
koncepcja baz danych NoSQL stała się popularna wśród internetowych gigantów, takich jak Google, Facebook, Amazon itp. którzy zajmują się ogromnymi ilościami danych. Czas reakcji systemu staje się powolny, gdy używasz RDBMS dla ogromnych ilości danych.
aby rozwiązać ten problem, możemy „skalować” nasze systemy poprzez modernizację naszego istniejącego sprzętu. Ten proces jest kosztowny.
alternatywą dla tego problemu jest dystrybucja obciążenia bazy danych na wielu hostach, gdy obciążenie wzrasta. Metoda ta jest znana jako ” skalowanie.,”

baza danych NoSQL jest nie relacyjna, więc skaluje się lepiej niż relacyjne bazy danych, ponieważ są zaprojektowane z myślą o aplikacjach internetowych.,ST z JSON
rozproszone
- wiele baz danych NoSQL może być uruchamianych w sposób rozproszony
- oferuje automatyczne skalowanie i funkcje fail-over
- często koncepcja ACID może być poświęcona dla skalowalności i przepustowości
- głównie brak synchronicznej replikacji między rozproszonymi węzłami replikacja multi-master, peer-to-peer, replikacja HDFS
- tylko zapewniająca ostateczną spójność
- współdzielona architektura nothing., Umożliwia to mniejszą koordynację i większą dystrybucję.

NoSQL nie jest współdzielony.
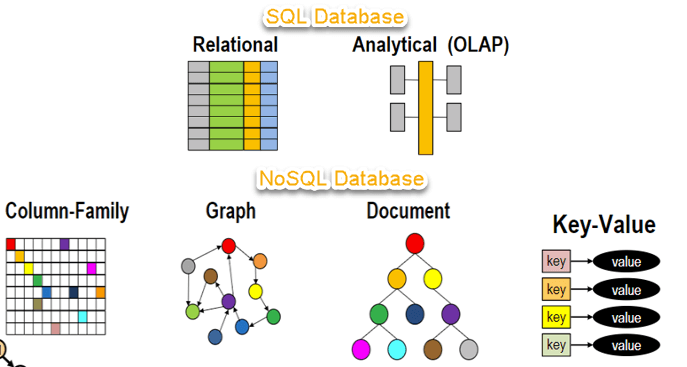
typy baz danych NoSQL
bazy danych NoSQL są podzielone głównie na cztery typy: para klucz-wartość, zorientowana na kolumny, oparta na wykresach i zorientowana na dokumenty. Każda kategoria ma swoje unikalne atrybuty i ograniczenia. Żadna z wyżej wymienionych baz danych nie jest lepsza do rozwiązania wszystkich problemów. Użytkownicy powinni wybrać bazę danych w oparciu o ich potrzeby produktu.,
typy baz danych NoSQL:
- para klucz-wartość oparta na
- Wykres zorientowany kolumnowo
- wykresy oparte na
- zorientowany na dokument

pary wartości klucza oparte na
dane są przechowywane w parach klucz/wartość. Został zaprojektowany w taki sposób, aby obsługiwać wiele danych i duże obciążenie.
przechowujące pary klucz-wartość bazy danych przechowują dane jako tabelę skrótu, w której każdy klucz jest unikalny, a wartością może być JSON, BLOB(binarne duże obiekty), string, itp.,
na przykład para klucz-wartość może zawierać klucz typu „Website” powiązany z wartością typu „Guru99”.

jest to jeden z najbardziej podstawowych przykładów bazy danych NoSQL. Tego rodzaju baza danych NoSQL jest używana jako zbiór, słowniki, tablice asocjacyjne itp. Magazyn wartości klucza pomaga programistom przechowywać dane bez schematu. Najlepiej sprawdzają się w przypadku zawartości koszyka.
Redis, Dynamo, Riak to przykłady NoSQL baz danych przechowujących klucz-wartość. Wszystkie są oparte na papierze Dynamo firmy Amazon.,
bazujące na kolumnach
bazujące na kolumnach bazują na BigTable paper firmy Google. Każda kolumna jest traktowana oddzielnie. Wartości baz danych pojedynczych kolumn są przechowywane obok siebie.

baza danych NoSQL oparta na kolumnach
zapewniają wysoką wydajność przy zapytaniach agregacyjnych, takich jak SUM, COUNT, AVG, MIN itp. ponieważ dane są łatwo dostępne w kolumnie.,
bazy danych NoSQL oparte na kolumnach są szeroko stosowane do zarządzania hurtowniami danych, business intelligence, CRM, katalogami kart bibliotecznych,
HBase, Cassandra, HBase, Hypertable są przykładami zapytań NoSQL baz danych opartych na kolumnach.
Document-Oriented:
Document-Oriented NoSQL DB przechowuje i pobiera dane jako parę wartości klucza, ale część wartości jest przechowywana jako dokument. Dokument jest przechowywany w formatach JSON lub XML. Wartość jest rozumiana przez DB i może być zapytana.

, Dokument
na tym diagramie po lewej stronie widać, że mamy wiersze i kolumny, a po prawej mamy bazę danych dokumentów, która ma podobną strukturę do JSON. Teraz dla relacyjnej bazy danych, musisz wiedzieć, jakie kolumny masz i tak dalej. Jednak w przypadku bazy danych dokumentów przechowuje się dane, takie jak obiekt JSON. Nie musisz definiować, które sprawiają, że jest elastyczny.
typ dokumentu jest najczęściej używany w systemach CMS, platformach blogowych, analizach w czasie rzeczywistym & aplikacjach e-commerce., Nie powinien być stosowany w przypadku złożonych transakcji, które wymagają wielu operacji lub zapytań przeciwko różnym strukturom agregatów.
Amazon SimpleDB, CouchDB, MongoDB, Riak, Lotus Notes, MongoDB, są popularnymi systemami DBMS pochodzącymi z dokumentów.
oparta na grafie
baza danych typu Graf przechowuje encje, a także relacje między tymi encjami. Encja jest przechowywana jako węzeł z relacją jako krawędzie. Krawędź daje relację między węzłami. Każdy węzeł i krawędź ma unikalny identyfikator.,

w porównaniu do relacyjnej bazy danych, w której tabele są luźno połączone, Grafowa baza danych ma charakter multi-relacyjny. Relacje przechodzące są szybkie, ponieważ są już przechwytywane do DB i nie ma potrzeby ich obliczania.
baza danych grafów wykorzystywana głównie w sieciach społecznościowych, logistyce, danych przestrzennych.
Neo4J, Infinite Graph, OrientDB, FlockDB to popularne bazy danych oparte na grafie.,
narzędzia mechanizmu zapytań dla NoSQL
najczęstszym mechanizmem wyszukiwania danych jest pobieranie wartości na podstawie klucza/ID z zasobu GET
baza danych magazynu dokumentów oferuje trudniejsze zapytania, ponieważ rozumie wartość pary klucz-wartość. Na przykład CouchDB umożliwia definiowanie widoków za pomocą MapReduce
czym jest twierdzenie CAP?
twierdzenie CAP jest również nazywane twierdzeniem Brewera., Stwierdza, że jest niemożliwe, aby rozproszony magazyn danych oferował więcej niż dwie z trzech gwarancji
- spójność
- dostępność
- tolerancja partycji
spójność:
dane powinny pozostać spójne nawet po wykonaniu operacji. Oznacza to, że po zapisaniu danych każde przyszłe żądanie odczytu powinno zawierać te dane. Na przykład po zaktualizowaniu statusu zamówienia wszyscy klienci powinni być w stanie zobaczyć te same dane.
dostępność:
baza danych powinna być zawsze dostępna i responsywna. Nie powinno mieć żadnych przestojów.,
tolerancja partycji:
tolerancja partycji oznacza, że system powinien nadal działać, nawet jeśli komunikacja między serwerami nie jest stabilna. Na przykład serwery mogą być podzielone na wiele grup, które mogą nie komunikować się ze sobą. Tutaj, jeśli część bazy danych jest niedostępna, Inne części są zawsze nienaruszone.
ewentualna spójność
termin „ewentualna spójność” oznacza posiadanie kopii danych na wielu komputerach w celu uzyskania wysokiej dostępności i skalowalności., Tak więc zmiany wprowadzone do dowolnej pozycji danych na jednej maszynie muszą być propagowane do innych replik.
replikacja danych może nie być natychmiastowa, ponieważ niektóre kopie będą aktualizowane natychmiast, a inne w odpowiednim czasie. Kopie te mogą być wzajemnie, ale w odpowiednim czasie stają się spójne. Stąd nazwa ewentualna konsekwencja.,i> zasadniczo, dostępne oznacza, że DB jest dostępny przez cały czas zgodnie z twierdzeniem CAP
