ce sunt Robot meta tag-uri?
Robots meta directives (uneori numite” meta tag-uri”) sunt bucăți de cod care oferă instrucțiuni de crawlere pentru accesarea cu crawlere sau indexarea conținutului paginii web. În timp ce roboți.directivele de fișiere TXT oferă sugestii de roboți pentru a accesa cu crawlere paginile unui site web, directivele meta ale roboților oferă instrucțiuni mai ferme despre cum să acceseze cu crawlere și să indexeze conținutul unei pagini.,există două tipuri de roboți meta directive: cele care fac parte din pagina HTML (cum ar fi meta robotstag) și cele pe care serverul web le trimite ca anteturi HTTP (cum ar fi X-robots-tag). Aceiași parametri (adică instrucțiunile de crawling sau indexare pe care le oferă o meta tag, cum ar fi” noindex „și” nofollow ” în exemplul de mai sus) pot fi utilizați atât cu meta robots, cât și cu X-robots-tag; ceea ce diferă este modul în care acești parametri sunt comunicați crawlerelor.,
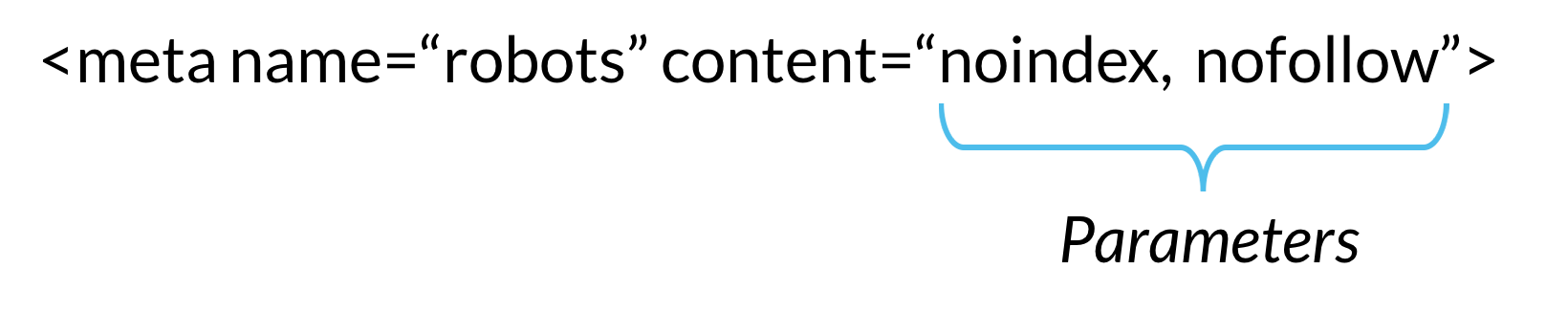
Meta directivele da crawlerele instrucțiuni despre cum să se târască și să indice informații se găsesc pe o anumită pagină web. Dacă aceste directive sunt descoperite de roboți, parametrii lor servesc ca sugestii puternice pentru comportamentul de indexare a crawlerului. Dar ca și în cazul roboților.fișierele txt, crawlerele nu trebuie să vă urmeze directivele meta, deci este un pariu sigur că unii roboți web rău intenționați vă vor ignora directivele.,
mai jos sunt parametrii pe care crawlerele motoarelor de căutare le înțeleg și le urmăresc atunci când sunt utilizate în meta directivele roboților. Parametrii nu sunt sensibili la majuscule și minuscule, dar rețineți că este posibil ca unele motoare de căutare să urmeze doar un subset al acestor parametri sau să trateze unele directive ușor diferit.
parametrii de control al indexării:
-
Noindex: spune unui motor de căutare să nu indexeze o pagină.
-
Index: spune unui motor de căutare să indexeze o pagină. Rețineți că nu este necesar să adăugați această etichetă meta; este implicit.,
-
Follow: chiar dacă pagina nu este indexată, crawler-ul ar trebui să urmeze toate linkurile dintr-o pagină și să transmită echitatea către paginile conectate.
-
Nofollow: îi spune unui crawler să nu urmeze niciun link dintr-o pagină sau să treacă de-a lungul niciunei echități de link.Noimageindex: spune unui crawler să nu indexeze nicio imagine dintr-o pagină.
-
None: echivalent cu utilizarea simultană a etichetelor noindex și nofollow.
-
Noarchive: motoarele de căutare nu ar trebui să afișeze un link în cache către această pagină pe un SERP.,Nocache: la fel ca noarchive, dar folosit doar de Internet Explorer și Firefox.
-
Nosnippet: spune unui motor de căutare să nu afișeze un fragment din această pagină (adică meta descriere) a acestei pagini pe un SERP.Noodyp / noydir: împiedică motoarele de căutare să utilizeze descrierea DMOZ a unei pagini ca fragment SERP pentru această pagină. Cu toate acestea, DMOZ a fost retras la începutul anului 2017, ceea ce face ca această etichetă să fie depășită.
-
Indisponibil_after: motoarele de căutare nu ar trebui să mai indexeze această pagină după o anumită dată.,
tipuri de roboți meta directive
există două tipuri principale de roboți meta directive: meta robots tag și X-robots-tag. Orice parametru care poate fi utilizat într-o etichetă meta robots poate fi, de asemenea, specificat într-o etichetă x-robots.
vom vorbi atât despre meta robots, cât și despre directivele etichetelor x-robots de mai jos.,pagina de cod HTML și apare ca elemente de cod într-o pagină web este <head> secțiunea:
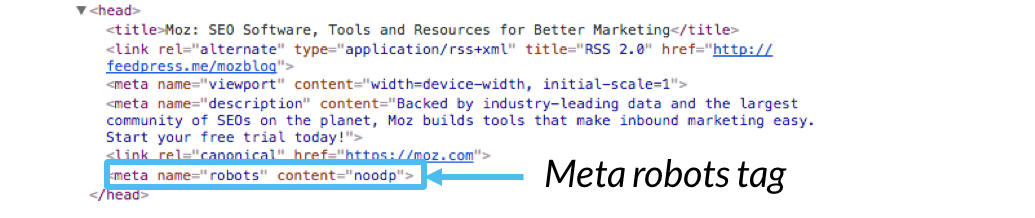
exemplu de Cod:
<pre><meta name=”robots” content=””></pre>
În timp ce generalul <meta name="robots" content=""> tag-ul este standard, puteți oferi, de asemenea, directivele specifice crawlerele prin înlocuirea „roboți”, cu numele de un anumit user-agent., De exemplu, pentru a viza o directivă în mod specific pentru Googlebot, ați folosi următorul cod:
<meta name="googlebot" content="">
doriți să utilizați mai multe directive pe o pagină? Atâta timp cât sunt direcționate către același „robot” (user-agent), mai multe directive pot fi incluse într – o meta directivă-separați-le doar prin virgule. Iată un exemplu:
<meta name="robots" content="noimageindex, nofollow, nosnippet">
această etichetă ar spune roboților să nu indexeze niciuna dintre imaginile dintr-o pagină, să urmeze oricare dintre linkuri sau să afișeze un fragment al paginii atunci când apare pe un SERP.,
dacă folosești diferite directive privind marcajele meta robots pentru diferiți utilizatori-agenți de căutare, va trebui să folosești etichete separate pentru fiecare bot.în timp ce eticheta meta robots vă permite să controlați comportamentul de indexare la nivel de pagină, eticheta x-robots poate fi inclusă ca parte a antetului HTTP pentru a controla indexarea unei pagini în ansamblu, precum și elemente foarte specifice ale unei pagini.,
în timp ce puteți utiliza eticheta X-robots-tag pentru a executa toate aceleași directive de indexare ca meta robots, Directiva x-robots-tag oferă mult mai multă flexibilitate și funcționalitate pe care eticheta meta robots nu o face. Mai exact, x-robots permite utilizarea expresiilor regulate, executarea directivelor de accesare cu crawlere pe fișiere non-HTML și aplicarea parametrilor la nivel global.
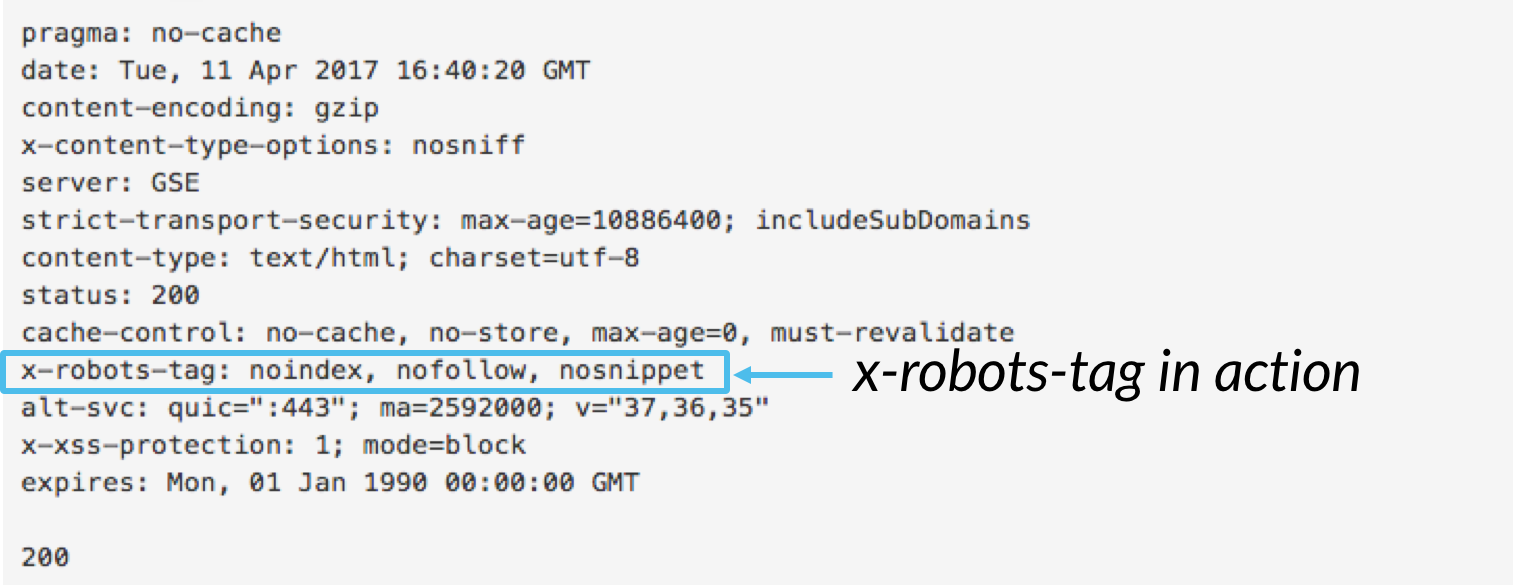
Pentru a folosi x-roboți-tag-ul, va trebui să aibă acces la site-ul dvs. antet .php, .htaccess sau fișier de acces la server., De acolo, adăugați marcajul x-robots-tag specific configurației serverului dvs., inclusiv parametrii. Acest articol oferă câteva exemple minunate despre aspectul marcajului x-robots-tag dacă utilizați oricare dintre aceste trei configurații.,Aici sunt câteva cazuri de utilizare pentru ce s-ar putea angaja x-roboți de tag-ul:
-
Controlul indexarea de conținut nu sunt scrise în HTML (cum ar fi flash sau video)
-
Blocarea indexării un anumit element dintr-o pagină (cum ar fi o imagine sau video), dar nu întreaga pagină în sine
-
Controlul indexare dacă nu aveți acces la o pagina HTML (în special, la <cap> secțiune) sau dacă site-ul utilizează un antet globale, care nu poate fi schimbat
-
Adăugarea de reguli pentru a stabili dacă este sau nu o pagină ar trebui să fie indexate (ex., Dacă un utilizator a comentat de peste 20 de ori, index pagina lor de profil)
cele mai bune practici SEO cu roboți meta directivele
-
Toate meta directive (roboți sau altfel) sunt descoperite atunci când un URL-ul este indexat. Acest lucru înseamnă că, dacă un roboți.fișier txt interzice URL-ul de la crawling, orice directivă meta pe o pagină (fie în HTML sau antetul HTTP) nu va fi văzut și va fi, în mod eficient, ignorate.în cele mai multe cazuri, utilizarea unei etichete meta robots cu parametrii „noindex, follow” ar trebui să fie folosită ca o modalitate de a restricționa accesarea cu crawlere sau indexarea în loc să folosiți roboți.,fișierul txt nu permite.este important să rețineți că crawlerele rău intenționate pot ignora complet directivele meta și, ca atare, acest protocol nu face un mecanism de securitate bun. Dacă aveți informații private pe care nu doriți să le faceți căutate în mod public, alegeți o abordare mai sigură, cum ar fi protecția prin parolă, pentru a împiedica vizitatorii să vizualizeze pagini confidențiale.
-
nu trebuie să utilizați atât meta roboți, cât și X-robots – tag pe aceeași pagină-acest lucru ar fi redundant.
păstrați învățarea
- roboți.,txt
- X-Robots-Tag: un simplu alternativ pentru roboți .txt și Meta Tag
- controlul crawlere motor de căutare pentru o mai bună indexare și clasamente
- roboți Meta Tag și X-roboți-Tag HTTP antet Specificații
pune-ți abilitățile la locul de muncă
Moz Pro vă permite să rulați crawlere, de cercetare și raport cu privire la rang de cuvinte cheie, și urmăriți performanța SEO site-ului, inclusiv accesibilitatea acestuia, în timp. Încercați > >