Was ist NoSQL?
NoSQL-Datenbank ist eine nicht-relationale Datenbank-Management-System, das erfordert keine eine festen schema. Es vermeidet Joins und ist einfach zu skalieren. Der Hauptzweck der Verwendung einer NoSQL-Datenbank besteht in verteilten Datenspeichern mit enormen Datenspeicheranforderungen. NoSQL wird für Big Data und Echtzeit-Web-Apps verwendet. Unternehmen wie Twitter, Facebook und Google sammeln beispielsweise jeden Tag Terabyte an Nutzerdaten.,
NoSQL database steht für“ Not Only SQL „oder“ Not SQL.“Obwohl ein besserer Begriff „NoREL“ wäre, fing NoSQL an. Carl Strozz führte das NoSQL-Konzept 1998 ein.
Herkömmliche RDBMS verwenden SQL-Syntax zum Speichern und Abrufen von Daten für weitere Erkenntnisse. Stattdessen umfasst ein NoSQL-Datenbanksystem eine breite Palette von Datenbanktechnologien, die strukturierte, halbstrukturierte, unstrukturierte und polymorphe Daten speichern können., Lassen Sie uns wissen über NoSQL mit einem Diagramm in diesem NoSQL-Datenbank-tutorial:
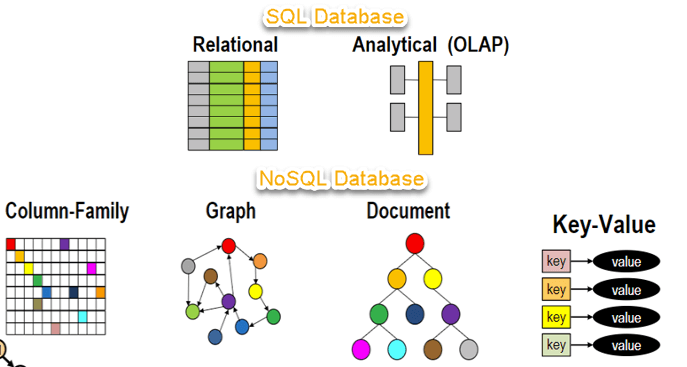
In diesem NoSQL – – tutorial für Anfänger lernen Sie, NoSQL Grundlagen wie:
- Warum NoSQL?
- Kurze Geschichte von NoSQL-Datenbanken
- Merkmale von NoSQL
- Arten von NoSQL-Datenbanken
- Abfragemechanismus Werkzeuge für NoSQL
- Was ist der CAP-Satz?
- Eventuelle Konsistenz
- Vorteile von NoSQL
Warum NoSQL?,
der Begriff Der NoSQL-Datenbanken wurde populär mit Internet-Giganten wie Google, Facebook, Amazon, etc. die mit riesigen Datenmengen umgehen. Die Reaktionszeit des Systems wird langsam, wenn Sie RDBMS für große Datenmengen verwenden.
Um dieses Problem zu lösen, können wir unsere Systeme durch ein Upgrade unserer vorhandenen Hardware“ skalieren“. Dieser Prozess ist teuer.
Die Alternative zu diesem Problem besteht darin, die Datenbanklast auf mehrere Hosts zu verteilen, wenn die Last zunimmt. Diese Methode wird als „Skalieren“ bezeichnet.,“

Die NoSQL-Datenbank ist nicht relational und skaliert daher besser als relationale Datenbanken, da sie für Webanwendungen entwickelt wurden.,ST mit JSON
Verteilte
- Mehrere NoSQL-Datenbanken können auf verteilte Weise ausgeführt werden
- Bietet automatische Skalierung und Fail-Over-Funktionen
- Oft kann das Konzept für Skalierbarkeit und Durchsatz geopfert werden
- Meistens keine synchrone Replikation zwischen verteilten Knoten Asynchrone Multi-Master-Replikation, peer-to-Peer, HDFS Replication
- Bietet nur eventuelle Konsistenz
- Shared Nothing Architecture., Dies ermöglicht eine geringere Koordination und eine höhere Verteilung.

NoSQL Freigegeben ist Nichts.
Arten von NoSQL-Datenbanken
NoSQL-Datenbanken werden hauptsächlich in vier Typen eingeteilt: Schlüssel-Wert-Paar, spaltenorientiert, diagrammbasiert und dokumentenorientiert. Jede Kategorie hat ihre einzigartigen Attribute und Einschränkungen. Keine der oben angegebenen Datenbanken ist besser, um alle Probleme zu lösen. Benutzer sollten die Datenbank basierend auf ihren Produktanforderungen auswählen.,
Typen von NoSQL-Datenbanken:
- Schlüssel-Wert-Paar Basierend
- Spaltenorientiertes Diagramm
- Diagramme basierend
- Dokumentorientiert

Schlüsselwertpaar Basierend
Daten werden in Schlüssel/Wert-Paaren gespeichert. Es ist so konzipiert, dass es viele Daten und schwere Lasten verarbeitet.
Schlüssel-Wert-Paar-Speicherdatenbanken speichern Daten als Hash-Tabelle, in der jeder Schlüssel eindeutig ist, und der Wert kann ein JSON, BLOB(binäre große Objekte), String usw. sein.,
Beispielsweise kann ein Schlüssel-Wert-Paar einen Schlüssel wie „Website“ enthalten, der einem Wert wie „Guru99″zugeordnet ist.

Es ist eines der wichtigsten NoSQL-Datenbank-Beispiel. Diese Art von NoSQL-Datenbank wird als Sammlung, Wörterbücher, assoziative Arrays usw. verwendet. Schlüsselwertspeicher helfen dem Entwickler, schemalose Daten zu speichern. Sie funktionieren am besten für Warenkorbinhalte.
Redis, Dynamo, Riak sind einige NoSQL-Beispiele für Schlüssel-Wert-Speicherdatenbanken. Sie basieren alle auf Amazons Dynamo-Papier.,
Column-based
spaltenorientierte Datenbanken arbeiten, die auf Spalten und basiert auf BigTable Papier durch Google. Jede Spalte wird separat behandelt. Werte von Einzelspaltendatenbanken werden zusammenhängend gespeichert.

Spalte basierten NoSQL-Datenbank
Sie bieten hohe performance auf aggregation Abfragen wie SUM, COUNT, AVG, MIN, etc. da die Daten in einer Spalte leicht verfügbar sind.,
Spaltenbasierte NoSQL-Datenbanken werden häufig zur Verwaltung von Data Warehouses, Business Intelligence, CRM, Bibliothekskartenkatalogen,
HBase, Cassandra, HBase und Hypertable verwendet NoSQL-Abfragebeispiele für spaltenbasierte Datenbanken.
Dokumentenorientiert:
Dokumentenorientiert NoSQL DB speichert und ruft Daten als Schlüsselwertpaar ab, der Werteteil wird jedoch als Dokument gespeichert. Das Dokument wird im JSON-oder XML-Format gespeichert. Der Wert wird von der DB verstanden und kann abgefragt werden.

Relationale Vs., Dokument
In diesem Diagramm auf der linken Seite sehen Sie, dass wir Zeilen und Spalten haben, und auf der rechten Seite haben wir eine Dokumentdatenbank, die eine ähnliche Struktur wie JSON hat. Für die relationale Datenbank müssen Sie nun wissen, welche Spalten Sie haben und so weiter. Für eine Dokumentdatenbank verfügen Sie jedoch über einen Datenspeicher wie ein JSON-Objekt. Sie müssen nicht definieren, welche es flexibel machen.
Der Dokumenttyp wird hauptsächlich für CMS-Systeme, Blogging-Plattformen und Echtzeitanalysen verwendet & E-Commerce-Anwendungen., Es sollte nicht für komplexe Transaktionen verwendet werden, die mehrere Operationen oder Abfragen gegen unterschiedliche Aggregatstrukturen erfordern.
Amazon SimpleDB, CouchDB, MongoDB, Riak, Lotus Notes, MongoDB sind beliebte Dokument stammt von DBMS-Systemen.
Graph-Based
Eine Graphtyp-Datenbank speichert Entitäten sowie die Beziehungen zwischen diesen Entitäten. Die Entität wird als Knoten mit der Beziehung als Kanten gespeichert. Eine Kante gibt eine Beziehung zwischen den Knoten. Jeder Knoten und jede Kante hat eine eindeutige Kennung.,

Im Vergleich zu einer relationalen Datenbank, in der Tabellen lose verbunden sind, ist eine Graphendatenbank eine multirelationale Datenbank. Die Durchquerungsbeziehung ist schnell, da sie bereits in der DB erfasst wurden, und sie müssen nicht berechnet werden.
Graphenbasisdatenbank, die hauptsächlich für soziale Netzwerke, Logistik und Geodaten verwendet wird.
Neo4J, Unendlichen Graphen, OrientDB, FlockDB, sind einige beliebte Grafik-basierte Datenbanken.,
Abfragemechanismus Werkzeuge für NoSQL
Der gebräuchlichste Datenabfragemechanismus ist der restbasierte Abruf eines Werts basierend auf seinem Schlüssel/seiner ID mit GET resource
Dokumentenspeicherdatenbank bietet schwierigere Abfragen, da sie den Wert in einem Schlüssel-Wert-Paar verstehen. Beispielsweise ermöglicht CouchDB das Definieren von Ansichten mit MapReduce
Was ist der CAP-Satz?
CAP-theorem wird auch als brewer ‚ s theorem., Es heißt, dass ein verteilter Datenspeicher nicht mehr als zwei von drei Garantien bieten kann
- Konsistenz
- Verfügbarkeit
- Partitionstoleranz
Konsistenz:
Die Daten sollten auch nach der Ausführung einer Operation konsistent bleiben. Das bedeutet, sobald Daten geschrieben sind, sollte jede zukünftige Leseanforderung diese Daten enthalten. Nach dem Aktualisieren des Bestellstatus sollten beispielsweise alle Clients dieselben Daten sehen können.
Verfügbarkeit:
Die Datenbank sollte immer verfügbar und ansprechbar sein. Es sollte keine Ausfallzeiten haben.,
Partitionstoleranz:
Partitionstoleranz bedeutet, dass das System auch dann weiter funktionieren sollte, wenn die Kommunikation zwischen den Servern nicht stabil ist. Beispielsweise können die Server in mehrere Gruppen unterteilt werden, die möglicherweise nicht miteinander kommunizieren. Wenn hier ein Teil der Datenbank nicht verfügbar ist, bleiben andere Teile immer unberührt.
Eventuelle Konsistenz
Der Begriff „eventuelle Konsistenz“ bedeutet, Kopien von Daten auf mehreren Computern zu haben, um eine hohe Verfügbarkeit und Skalierbarkeit zu erzielen., Daher müssen Änderungen an Datenelementen auf einem Computer an andere Replikate weitergegeben werden.
Die Datenreplikation erfolgt möglicherweise nicht sofort, da einige Kopien sofort aktualisiert werden, während andere zu gegebener Zeit aktualisiert werden. Diese Kopien können gegenseitig sein, aber zu gegebener Zeit werden sie konsistent. Daher der Name eventuelle Konsistenz.,i> Grundsätzlich verfügbare Mittel DB ist die ganze Zeit gemäß CAP-Theorem verfügbar

Vorteile von NoSQL
- Können als Primär-oder Analytische Datenquelle
- Big Data-Fähigkeit
- Kein einzelner Fehlerpunkt
- Einfache Replikation
- Keine separate Caching-Schicht erforderlich
- Es bietet schnelle Leistung und horizontale Skalierbarkeit.,
- Kann strukturierte, halbstrukturierte und unstrukturierte Daten mit gleicher Wirkung verarbeiten
- Objektorientierte Programmierung, die einfach zu bedienen und flexibel ist
- NoSQL-Datenbanken benötigen keinen dedizierten Hochleistungsserver
- Unterstützung wichtiger Entwicklersprachen und-plattformen
- Einfach zu implementieren als die Verwendung von RDBMS
- Es kann als primäre Datenquelle für Online-Anwendungen dienen.,ariety, Volumen und Komplexität
- Zeichnet sich durch verteilte Datenbank-und Multi-Datacenter-Operationen aus
- Eliminiert die Notwendigkeit einer bestimmten Caching-Schicht zum Speichern von Daten
- Bietet ein flexibles Schemadesign, das ohne Ausfallzeiten oder Serviceunterbrechungen leicht geändert werden kann
Nachteile von NoSQL
- Keine Standardisierungsregeln
- Begrenzte Abfragefunktionen
- RDBMS-Datenbanken und-Tools sind vergleichsweise ausgereift
- Es bietet keine herkömmlichen Datenbankfunktionen, z. B. Konsistenz, wenn mehrere Transaktionen gleichzeitig ausgeführt werden.,
- Wenn das Datenvolumen zunimmt, ist es schwierig, eindeutige Werte beizubehalten, da Schlüssel schwierig werden
- Funktioniert nicht so gut mit relationalen Daten
- Die Lernkurve ist steif für neue Entwickler
- Open-Source-Optionen, die für Unternehmen nicht so beliebt sind.
Zusammenfassung
- NoSQL ist ein nicht-relationales DMS, das kein festes Schema erfordert, Joins vermeidet und einfach zu skalieren ist
- Das Konzept der NoSQL-Datenbanken warwurde bei Internetgiganten wie Google, Facebook, Amazon usw. beliebt., wer sich im Jahr 1998 mit riesigen Datenmengen beschäftigt
- – Carlo Strozzi verwendet den Begriff NoSQL für seine leichte, Open-Source-relationale Datenbank
- NoSQL-Datenbanken folgen niemals dem relationalen Modell Es ist entweder schemafrei oder hat entspannte Schemata
- Vier Arten von NoSQL-Datenbanken sind 1).Schlüssel-Wert-Paar (2).Säulenorientiertes Diagramm 3). Graphen-basierte 4).,Dokumentenorientiert
- NOSQL kann strukturierte, halbstrukturierte und unstrukturierte Daten mit gleicher Wirkung verarbeiten
- Der CAP-Satz besteht aus drei Wörtern Konsistenz, Verfügbarkeit und Partitionstoleranz
- BASE steht für grundsätzlich verfügbaren, weichen Zustand, eventuelle Konsistenz
- Der Begriff „eventuelle Konsistenz“ bedeutet, Kopien von Daten auf mehreren Computern zu haben, um eine hohe Verfügbarkeit und Skalierbarkeit zu erzielen
- NOSQL bietet begrenzte Abfragefunktionen