Was sind robot meta tags?
Roboter Meta-Direktiven (manchmal auch als „Meta-Tags“ bezeichnet) sind Codeteile, die Crawler Anweisungen zum Crawlen oder Indizieren von Webseiteninhalten enthalten. Während Roboter.txt-Dateianweisungen geben Bots Vorschläge zum Crawlen der Seiten einer Website, während Metaanweisungen festere Anweisungen zum Crawlen und Indizieren des Inhalts einer Seite enthalten.,
Es gibt zwei Arten von Meta-Direktiven für Roboter: solche, die Teil der HTML-Seite sind (wie der Meta-Robotstag), und solche, die der Webserver als HTTP-Header sendet (z. B. x-robots-tag). Die gleichen Parameter (dh die Crawling-oder Indizierungsanweisungen, die ein Meta-Tag bereitstellt, wie „noindex“ und „nofollow“ im obigen Beispiel) können sowohl mit Meta-Robotern als auch mit dem x-robots-Tag verwendet werden.,
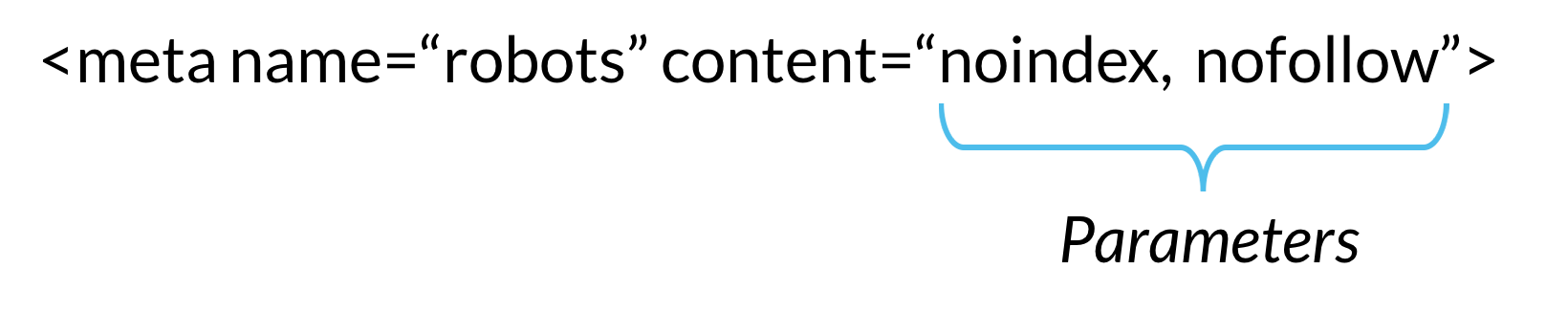
Meta-Direktiven geben Crawlern Anweisungen zum Crawlen und Indizieren von Informationen, die sie auf einer bestimmten Webseite finden. Wenn diese Direktiven von Bots erkannt werden, dienen ihre Parameter als starke Vorschläge für das Crawler-Indexierungsverhalten. Aber wie bei Robotern.txt-Dateien, Crawler müssen Ihren Meta-Anweisungen nicht folgen, daher ist es eine sichere Wette, dass einige böswillige Webroboter Ihre Anweisungen ignorieren.,
Unten sind die Parameter, die Suchmaschinen-Crawler verstehen und folgen, wenn sie in Roboter Meta-Direktiven verwendet werden. Die Parameter sind nicht groß-und Kleinschreibung, aber beachten Sie, dass es möglich ist, dass einige Suchmaschinen nur einer Teilmenge dieser Parameter folgen oder einige Richtlinien etwas anders behandeln.
Indexierungssteuernde Parameter:
-
Noindex: Weist eine Suchmaschine an, eine Seite nicht zu indizieren.
-
Index: Weist eine Suchmaschine an, eine Seite zu indizieren. Beachten Sie, dass Sie dieses Meta-Tag nicht hinzufügen müssen; es ist der Standard.,
-
Folgen: Auch wenn die Seite nicht indiziert ist, sollte der Crawler allen Links auf einer Seite folgen und sie an die verknüpften Seiten übergeben.
-
Nofollow: Weist einen Crawler an, keinen Links auf einer Seite zu folgen oder Links weiterzugeben.
-
Noimageindex: Weist einen Crawler an, keine Bilder auf einer Seite zu indizieren.
-
None: Entspricht der gleichzeitigen Verwendung der noindex-und nofollow-Tags.
-
Noarchive: Suchmaschinen sollten keinen zwischengespeicherten Link zu dieser Seite auf einem SERP anzeigen.,
-
Nocache: Wie noarchive, wird aber nur von Internet Explorer und Firefox verwendet.
-
Nosnippet: Weist eine Suchmaschine an, kein Snippet dieser Seite (dh Meta-Beschreibung) dieser Seite auf einem SERP anzuzeigen.
-
Noodyp / noydir: Verhindert, dass Suchmaschinen die DMOZ-Beschreibung einer Seite als SERP-Snippet für diese Seite verwenden. Anfang 2017 wurde DMOZ jedoch in den Ruhestand versetzt, wodurch dieses Tag obsolet wurde.
-
Unavailable_after: Suchmaschinen sollten diese Seite nach einem bestimmten Datum nicht mehr indizieren.,
Typen von Robotern Meta-Direktiven
Es gibt zwei Haupttypen von Robotern Meta-Direktiven: die Meta-Roboter-Tag und die x-Roboter-Tag. Jeder Parameter, der in einem Meta Robots-Tag verwendet werden kann, kann auch in einem x-robots-Tag angegeben werden.
Wir werden unten sowohl über die Meta-Roboter als auch über die x-Robots-Tag-Direktiven sprechen.,HTML-Code der Seite und erscheint als Code-Elemente innerhalb einer Webseite <head> Abschnitt:
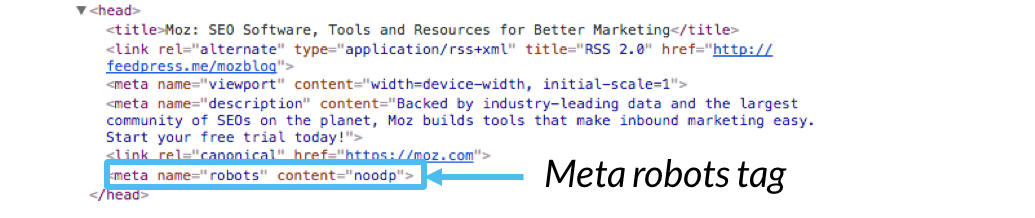
Codebeispiel:
<pre><meta name=“robots“ content=““></pre>
Während die allgemeine <meta name="robots" content=""> tag ist Standard, Sie können auch Anweisungen für bestimmte Crawler bereitstellen, indem Sie die „Roboter“ durch den Namen eines bestimmten Benutzeragenten ersetzen., Um beispielsweise eine Direktive speziell auf Googlebot auszurichten, verwenden Sie den folgenden Code:
<meta name="googlebot" content="">
Möchten Sie mehr als eine Direktive auf einer Seite verwenden? Solange sie auf denselben „Roboter“ (User-Agent) ausgerichtet sind, können mehrere Direktiven in einer Meta – Direktive enthalten sein-trennen Sie sie einfach durch Kommas. Hier ist ein Beispiel:
<meta name="robots" content="noimageindex, nofollow, nosnippet">
Dieses Tag weist Roboter an, keines der Bilder auf einer Seite zu indizieren, keinem der Links zu folgen oder ein Snippet der Seite anzuzeigen, wenn es auf einem SERP angezeigt wird.,
Wenn Sie verschiedene Meta-Tag-Direktiven für verschiedene Suchbenutzeragenten verwenden, müssen Sie für jeden Bot separate Tags verwenden.
X-robots-tag
Mit dem Meta robots-Tag können Sie das Indizierungsverhalten auf Seitenebene steuern, Das x-robots-Tag kann jedoch als Teil des HTTP-Headers enthalten sein, um die Indizierung einer Seite als Ganzes sowie ganz bestimmter Elemente einer Seite zu steuern.,
Während Sie mit dem x-robots-Tag dieselben Indexierungsanweisungen wie Meta-Roboter ausführen können, bietet die x-robots-tag-Direktive deutlich mehr Flexibilität und Funktionalität als das Meta-Robots-Tag nicht. Insbesondere ermöglicht der x-Roboter die Verwendung regulärer Ausdrücke, die Ausführung von Crawl-Direktiven für Nicht-HTML-Dateien und die Anwendung von Parametern auf globaler Ebene.
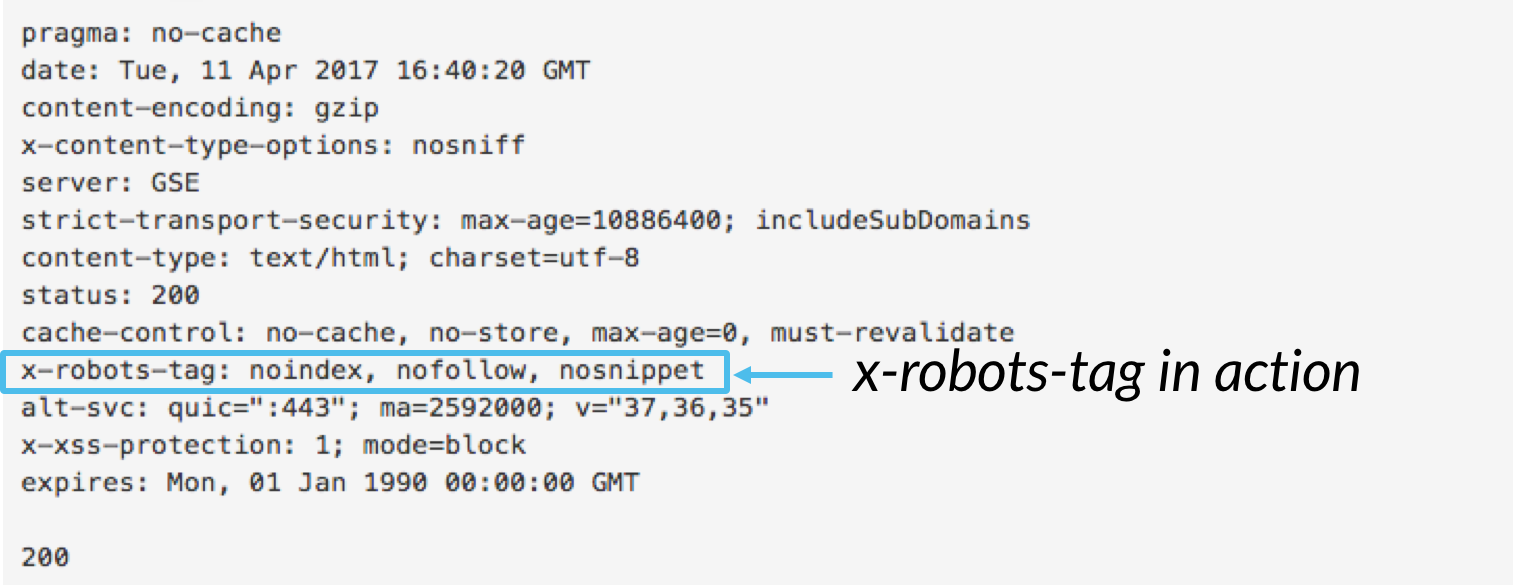
Um das x-robots-Tag zu verwenden, müssen Sie entweder auf den Header Ihrer Website zugreifen können .PHP, .htaccess -, oder server-access-Datei., Fügen Sie von dort aus das x-Robots-Tag-Markup Ihrer spezifischen Serverkonfiguration hinzu, einschließlich aller Parameter. Dieser Artikel enthält einige großartige Beispiele dafür, wie das X-Roboter-Tag-Markup aussieht, wenn Sie eine dieser drei Konfigurationen verwenden.,Hier sind einige Anwendungsfälle, warum Sie das x-robots-Tag verwenden können:
-
Steuern der Indexierung von Inhalten, die nicht in HTML geschrieben sind (wie Flash oder Video)
-
Blockieren der Indexierung eines bestimmten Elements einer Seite (wie eines Bildes oder Videos), aber nicht der gesamten Seite selbst
-
Steuern der Indexierung, wenn Sie keinen Zugriff auf den HTML-Code einer Seite haben (insbesondere auf die <head> section) oder wenn Ihre Site einen globalen Header verwendet, der nicht geändert werden kann
-
Hinzufügen von Regeln, ob eine Seite indiziert werden soll oder nicht (z., Wenn ein Benutzer über 20 Mal kommentiert hat, indizieren Sie seine Profilseite)
SEO Best Practices mit Robotern Meta-Direktiven
-
Alle Meta-Direktiven (Roboter oder auf andere Weise) werden beim Crawlen einer URL entdeckt. Dies bedeutet, dass, wenn ein Roboter.txt-Datei verbietet das Crawlen der URL, jede Meta-Direktive auf einer Seite (entweder im HTML-oder im HTTP-Header) wird nicht angezeigt und effektiv ignoriert.
-
In den meisten Fällen sollte die Verwendung eines Meta robots-Tags mit den Parametern „noindex, follow“ verwendet werden, um das Crawlen oder Indexieren einzuschränken, anstatt Roboter zu verwenden.,txt-Datei nicht erlaubt.
-
Es ist wichtig zu beachten, dass bösartige Crawler Meta-Direktiven wahrscheinlich vollständig ignorieren und dieses Protokoll daher keinen guten Sicherheitsmechanismus darstellt. Wenn Sie über private Informationen verfügen, die Sie nicht öffentlich durchsuchbar machen möchten, wählen Sie einen sichereren Ansatz, z. B. Passwortschutz, damit Besucher vertrauliche Seiten nicht anzeigen können.
-
Sie müssen nicht sowohl Meta-Roboter als auch das x-robots-Tag auf derselben Seite verwenden – dies wäre redundant.
Lernen Sie weiter
- Roboter.,txt
- X-Robots-Tag: Eine Einfache Alternative Für Roboter .txt und Meta-Tag
- Steuerung von Suchmaschinen-Crawler für eine bessere Indexierung und Rankings
- Roboter Meta-Tag und X-Roboter-Tag HTTP-Header-Spezifikationen
Setzen Sie Ihre Fähigkeiten zu arbeiten
Moz Pro können Sie Crawls, Forschung und Bericht über Keyword-Ranking, und verfolgen Sie Ihre Website SEO-Leistung, einschließlich seiner Zugänglichkeit, im Laufe der Zeit. Probieren Sie es >>