O que são meta-etiquetas de robôs?
robôs Meta diretivas (algumas vezes chamadas de “meta tags”) são peças de código que fornecem instruções para rastrear ou indexar conteúdo de páginas web. Enquanto robôs.as diretivas de arquivos txt dão sugestões de bots para como rastejar as páginas de um site, robôs meta diretivas fornecem instruções mais firmes sobre como rastejar e indexar o conteúdo de uma página.,
Existem dois tipos de robôs meta diretivas: aquelas que fazem parte da página HTML (como o meta robotstag) e aquelas que o servidor web envia como cabeçalhos HTTP (como x-robots-tag). Os mesmos parâmetros (ou seja, as instruções de rastreamento ou indexação que uma meta tag fornece, como “noindex” e “nofollow” no exemplo acima) podem ser usados tanto com meta robôs quanto com x-robôs-tag; o que difere é como esses parâmetros são comunicados a crawlers.,
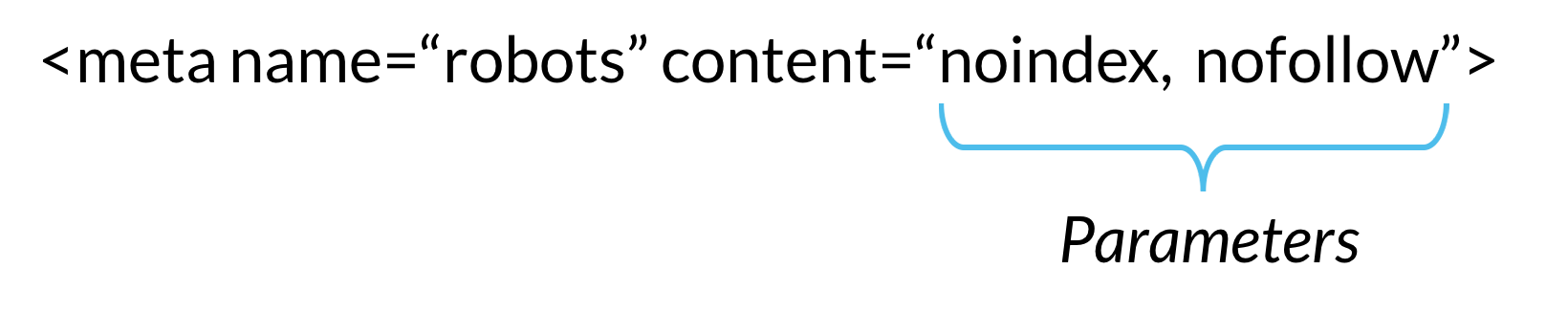
Meta directivas dar rastreadores instruções sobre como rastrear e indexar as informações que eles encontram em uma página da web específica. Se essas diretivas são descobertas por bots, seus parâmetros servem como fortes sugestões para o comportamento de indexação de crawler. Mas como com os robôs.arquivos txt, crawlers não têm que seguir suas diretivas meta, então é uma aposta segura que alguns robôs maliciosos da web vão ignorar suas diretivas.,
abaixo estão os parâmetros que os rastreadores de busca entendem e seguem quando eles são usados em robôs Meta diretivas. Os parâmetros não são sensíveis a maiúsculas, mas note que é possível que alguns motores de busca Apenas sigam um subconjunto destes parâmetros ou possam tratar algumas diretivas de forma ligeiramente diferente.
parâmetros de Controlo da indexação:
-
Noindex: diz a um motor de busca para não indexar uma página.
-
Índice: diz a um motor de busca para indexar uma página. Repare que não precisa de adicionar esta marca de meta; é por omissão.,
-
siga: mesmo que a página não seja indexada, o rastreador deve seguir todas as ligações de uma página e passar o capital próprio para as páginas ligadas.
-
Nofollow: diz a um rastreador para não seguir quaisquer links em uma página ou passar ao longo de qualquer link equity.
-
Noimageindex: diz a um rastreador para não indexar quaisquer imagens em uma página.
-
nenhuma: equivalente a usar simultaneamente as etiquetas noindex e nofollow.
-
Noarchive: os motores de busca não devem mostrar um link em cache para esta página em um SERP.,
-
Nocache: o mesmo que noarchive, mas usado apenas pelo Internet Explorer e Firefox.
-
Nosnippet: diz a um motor de busca para não mostrar um excerto desta página (ou seja, uma meta descrição) desta página num SERP.
-
Noodyp / noydir : impede os motores de busca de usar a descrição de uma página DMOZ como o excerto SERP para esta página. No entanto, a DMOZ foi aposentada no início de 2017, tornando esta tag obsoleta.
-
Indisponível_após: os motores de busca não devem indexar mais esta página após uma determinada data.,
Tipos de robots meta directivas
Existem dois tipos principais de robots meta directivas: a meta robots tag e o x-robots-tag. Qualquer parâmetro que possa ser usado em uma tag de meta robôs também pode ser especificado em uma tag x-robots-tag.vamos falar sobre os meta robôs e as diretivas X-robots abaixo.,página código HTML e aparece como elementos de código dentro de uma página da web <head> seção:
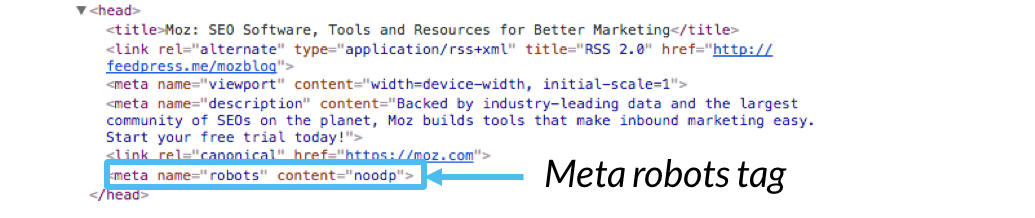
exemplo de Código:
<pre><meta name=”robots” content=””></pre>
Enquanto o <meta name="robots" content=""> tag é padrão, você também pode fornecer directivas para rastreadores específicos, substituindo os “robôs” com o nome de um usuário específico do agente., Por exemplo, para direcionar uma diretiva especificamente para o Googlebot, você usaria o seguinte código:
<meta name="googlebot" content="">
deseja usar mais do que uma diretiva em uma página? Desde que eles sejam direcionados para o mesmo “robô” (usuário-agente), várias diretivas podem ser incluídas em uma meta diretriz – apenas separá-los por vírgulas. Aqui está um exemplo:
<meta name="robots" content="noimageindex, nofollow, nosnippet">
Esta marca iria dizer aos robôs para não indexar nenhuma das imagens em uma página, seguir qualquer uma das ligações, ou mostrar um trecho da página quando ela aparece em um SERP.,
Se estiver a usar diferentes directivas de marcas de meta-robôs para diferentes agentes de pesquisa, terá de usar marcas separadas para cada Robot.
X-robots-tag
Enquanto a meta robots tag permite que você controle a indexação de comportamento no nível de página, o x-robots-tag pode ser incluído como parte do cabeçalho HTTP para controlar a indexação de uma página como um todo, bem como os elementos específicos de uma página.,
embora possa usar a marca x-robots para executar todas as mesmas directivas de indexação que os meta robots, a Directiva X-robots-tag oferece significativamente mais flexibilidade e funcionalidade que a marca meta robots não. Especificamente, OS X-robots permitem o uso de Expressões Regulares, executando diretivas crawl em arquivos não HTML, e aplicando parâmetros em um nível global.
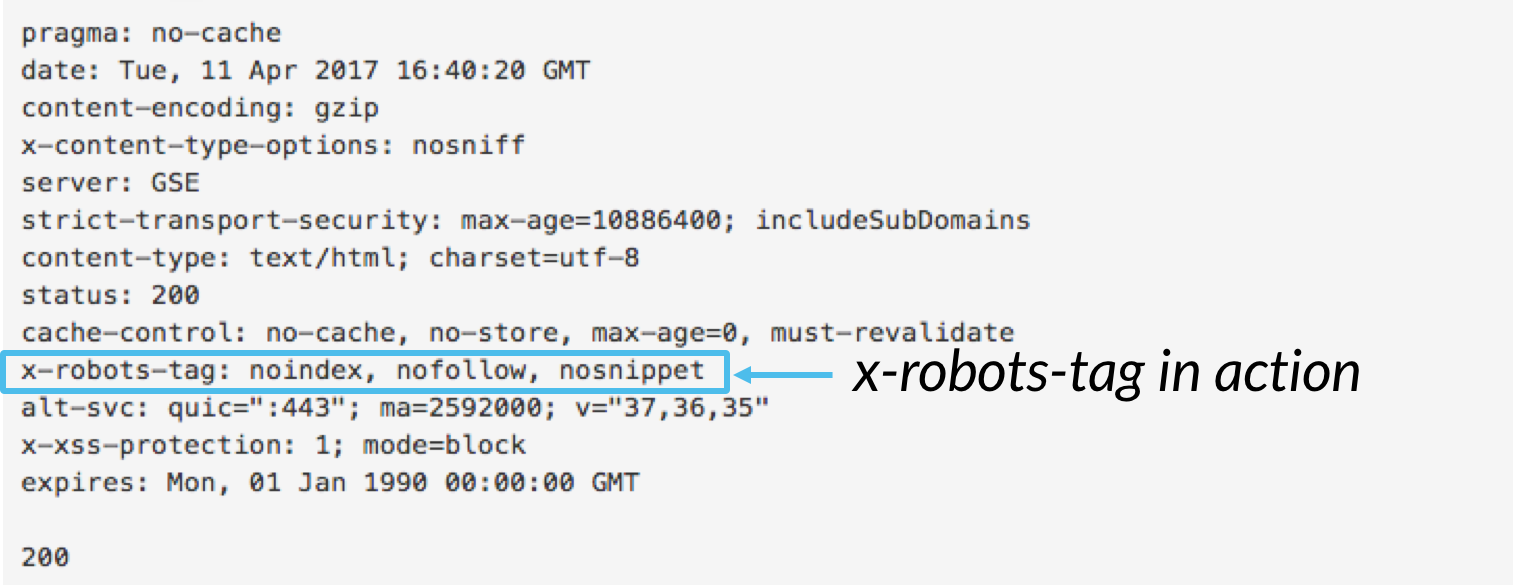
pai, .htaccess ou ficheiro de acesso ao servidor., A partir daí, adicione a marcação x-robots da configuração específica do seu servidor, incluindo quaisquer parâmetros. Este artigo fornece alguns bons exemplos de como a marcação X-robots-tag se parece se você estiver usando qualquer uma dessas três configurações.,Aqui estão alguns casos de uso para o qual você pode empregar o x-robots-tag:
-
Controlar a indexação de conteúdo escritos em HTML (como o flash ou vídeo)
-
Bloqueio de indexação de um determinado elemento de uma página (como uma imagem ou vídeo), mas não de toda a página em si
-
Controlando a indexação, se você não tem acesso a uma página HTML (mais especificamente, para o <head> seção) ou se o seu site usa uma global de cabeçalho que não pode ser alterado
-
Adicionando regras a existência ou não de uma página deve ser indexada (ex., Se um usuário comentou mais de 20 vezes, indexe sua página de perfil)
SEO melhores práticas com robôs meta diretivas
-
Todas as meta diretivas (robôs ou de outra forma) são descobertas quando um URL é rastejado. Isto significa que se um robô.o arquivo txt desvia a URL de rastreamento, qualquer meta diretriz em uma página (tanto no HTML como no cabeçalho HTTP) não será visto e, efetivamente, será ignorado.
-
na maioria dos casos, usando uma marca de meta robôs com parâmetros “noindex, follow” deve ser empregado como uma maneira de restringir o rastejar ou indexação em vez de usar robôs.,o ficheiro txt não permite.
-
é importante notar que rastejantes maliciosos são susceptíveis de ignorar completamente Meta diretivas e, como tal, este protocolo não faz um bom mecanismo de segurança. Se você tem informações privadas que você não quer tornar publicamente pesquisável, escolha uma abordagem mais segura, como a proteção de senha, para evitar que os visitantes visualizem páginas confidenciais.
-
não precisa de usar tanto os meta-robots como a marca x-robots na mesma página – fazê-lo seria redundante.
Keep learning
- Robots.,txt
- X-Robots-Tag: um simples alternativo para Robôs .txt e Meta Tag
- Controlling Search Engine Crawlers for Better Indexation and Rankings
- Robots Meta Tag and X-Robots-Tag HTTP Header Specifications