czym są meta tagi robotów?
meta dyrektywy robotów (czasami nazywane „meta tagami”) to fragmenty kodu, które zawierają instrukcje indeksowania lub indeksowania zawartości stron internetowych. Podczas gdy roboty.dyrektywy plików txt dają boty sugestie, jak indeksować strony witryny, a meta dyrektywy robotów zawierają bardziej szczegółowe instrukcje, jak indeksować i indeksować zawartość strony.,
istnieją dwa typy meta dyrektyw robotów: te, które są częścią strony HTML (jak Meta robotstag) oraz te, które serwer WWW wysyła jako nagłówki HTTP (takie jak X-robots-tag). Te same parametry (np. instrukcje indeksowania lub indeksowania dostarczane przez meta tag, takie jak „noindex” i „nofollow” w powyższym przykładzie) mogą być używane zarówno z meta robotami, jak i X-robots-tag; różni się to, w jaki sposób te parametry są przekazywane do indeksujących.,
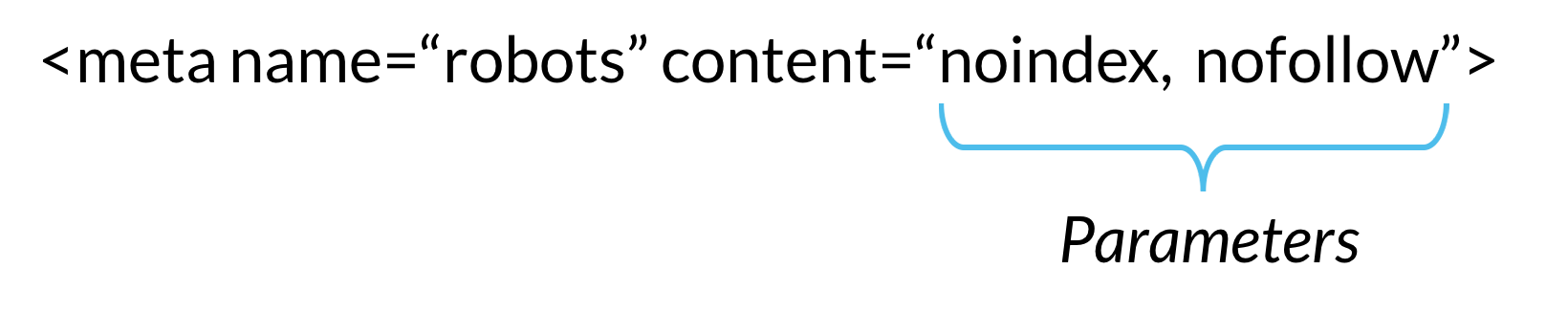
dyrektywy Meta zawierają instrukcje indeksowania i indeksowania informacji, które znajdują się na określonej stronie internetowej. Jeśli dyrektywy te zostaną wykryte przez boty, ich parametry służą jako silne sugestie dotyczące indeksacji gąsienic. Ale jak z robotami.pliki txt, crawlery nie muszą podążać za twoimi dyrektywami meta, więc jest to Bezpieczny zakład, że niektóre złośliwe roboty internetowe zignorują Twoje dyrektywy.,
poniżej znajdują się parametry, które gąsienice wyszukiwarek rozumieją i podążają za nimi, gdy są używane w Meta-dyrektywach robotów. Parametry nie uwzględniają wielkości liter, ale należy pamiętać, że możliwe, że niektóre wyszukiwarki mogą śledzić tylko podzbiór tych parametrów lub mogą traktować niektóre dyrektywy nieco inaczej.
indeksacja-parametry sterujące:
-
Noindex: mówi wyszukiwarce, aby nie indeksowała strony.
-
Index: nakazuje wyszukiwarce indeksowanie strony. Zauważ, że nie musisz dodawać tego znacznika meta-jest to wartość domyślna.,
-
Follow: nawet jeśli strona nie jest indeksowana, crawler powinien podążać za wszystkimi linkami na stronie i przekazać equity do połączonych stron.
-
Nofollow: mówi crawlerowi, aby nie śledził żadnych linków na stronie ani nie przekazywał żadnych linków.
-
Noimageindex: mówi crawlerowi, aby nie indeksował żadnych obrazów na stronie.
-
None: odpowiednik używania jednocześnie tagów noindex i nofollow.
-
Noarchive: Wyszukiwarki nie powinny pokazywać buforowanego linku do tej strony na serwerze.,
-
Nocache: taki sam jak noarchive, ale używany tylko przez Internet Explorer i Firefox.
-
Nosnippet: mówi wyszukiwarce, aby nie pokazywała fragmentu tej strony (tj. meta opisu) tej strony na SERP.
-
Noodyp / noydir : uniemożliwia wyszukiwarkom używanie opisu DMOZ strony jako fragmentu SERP dla tej strony. Jednak ODP został wycofany na początku 2017 roku, przez co ten tag stał się przestarzały.
-
Unavailable_after: Wyszukiwarki nie powinny już indeksować tej strony po określonej dacie.,
typy dyrektyw robotów meta
istnieją dwa główne typy dyrektyw robotów meta: znacznik meta robots i znacznik X-robots. Każdy parametr, który może być użyty w Meta robots tag, może być również określony w X-robots-tag.
poniżej omówimy zarówno dyrektywy tagów meta robots, jak i X-robots.,kod HTML strony i pojawia się jako elementy kodu w sekcji <head> sekcja:
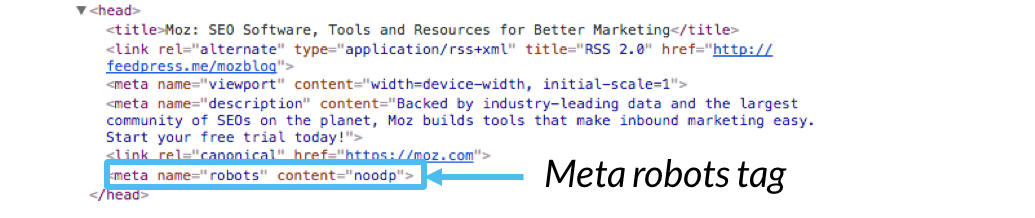
próbka kodu:
<Pre><meta name=”roboty” content=””></pre>
podczas gdy znacznik General <meta name="robots" content=""> jest standardem, możesz również dostarczyć dyrektywy do określonych robotów, zastępując „roboty” nazwą konkretnego agenta użytkownika., Na przykład, aby skierować dyrektywę konkretnie do Googlebota, należy użyć następującego kodu:
<meta name="googlebot" content="">
chcesz użyć więcej niż jednej dyrektywy na stronie? Tak długo, jak są one skierowane do tego samego „robota” (user-agenta), wiele dyrektyw może być zawartych w jednej meta dyrektywie – wystarczy rozdzielić je przecinkami. Oto przykład:
<meta name="robots" content="noimageindex, nofollow, nosnippet">
ten tag mówi robotom, aby nie indeksowały żadnych obrazów na stronie, nie podążały za żadnym z linków ani nie pokazywały fragmentu strony, gdy pojawia się na SERP.,
Jeśli używasz różnych dyrektyw tagów Meta robotów dla różnych wyszukiwarek, musisz użyć oddzielnych tagów dla każdego bota.
X-robots-tag
podczas gdy meta robots pozwala kontrolować zachowanie indeksowania na poziomie strony, X-robots-tag może być dołączony jako część nagłówka HTTP, aby kontrolować indeksowanie strony jako całości, a także bardzo konkretnych elementów strony.,
chociaż można używać X-robots-tag do wykonywania wszystkich tych samych dyrektyw indeksacji co meta robots, dyrektywa x-robots-tag oferuje znacznie większą elastyczność i funkcjonalność niż znacznik meta robots. W szczególności x-robots pozwala na użycie wyrażeń regularnych, wykonywanie dyrektyw crawl na plikach innych niż HTML i stosowanie parametrów na poziomie globalnym.
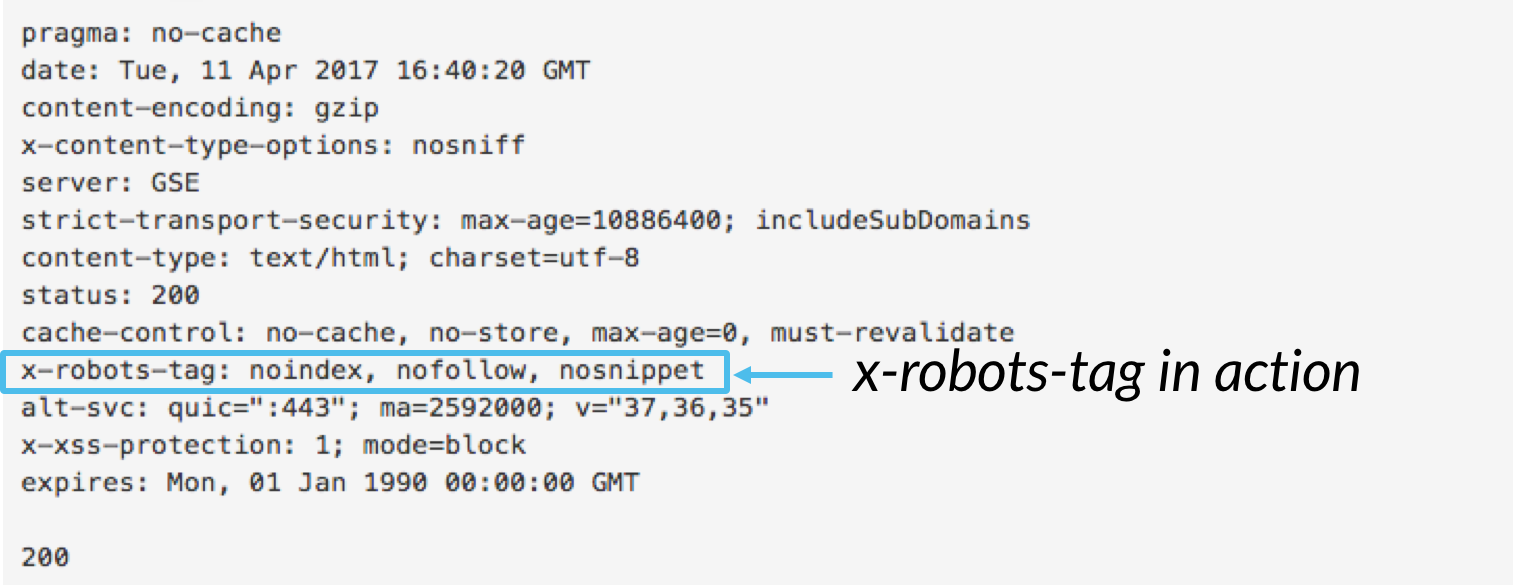
aby użyć tagu X-robots, musisz mieć dostęp do nagłówka Twojej witryny .php,htaccess, czyli plik dostępu do serwera., Następnie dodaj znaczniki X-robots-tag konfiguracji serwera, w tym dowolne parametry. Ten artykuł zawiera kilka świetnych przykładów tego, jak wygląda znacznik X-robots-tag, jeśli używasz jednej z tych trzech konfiguracji.,Poniżej znajduje się kilka przypadków użycia tagu X-robots:
-
kontrolowanie indeksacji treści nie napisanych w HTML (jak flash lub wideo)
-
blokowanie indeksacji określonego elementu strony (jak obraz lub wideo), ale nie całej strony
-
kontrolowanie indeksacji, jeśli nie masz dostępu do HTML strony (w szczególności do <head> section) lub jeśli Twoja strona używa globalnego nagłówka, którego nie można zmienić
-
dodawanie reguł do tego, czy strona ma być indeksowana (np., Jeśli użytkownik skomentował ponad 20 razy, indeksuj swoją stronę profilu)
najlepsze praktyki SEO z robotami meta dyrektywy
-
wszystkie meta dyrektywy (roboty lub inne) są wykrywane podczas indeksowania adresu URL. Oznacza to, że jeśli roboty.plik txt uniemożliwia indeksowanie adresu URL, Żadna dyrektywa meta na stronie (w nagłówku HTML lub HTTP) nie będzie widoczna i będzie skutecznie ignorowana.
-
w większości przypadków używanie znacznika meta robots o parametrach „noindex, follow” powinno być stosowane jako sposób na ograniczenie indeksowania lub indeksowania zamiast używania robotów.,plik txt jest wyłączany.
-
ważne jest, aby pamiętać, że złośliwe crawlery mogą całkowicie ignorować meta dyrektywy i jako takie protokół ten nie jest dobrym mechanizmem bezpieczeństwa. Jeśli masz prywatne informacje, których nie chcesz publicznie przeszukiwać, wybierz bardziej bezpieczne podejście, takie jak ochrona hasłem, aby uniemożliwić odwiedzającym przeglądanie poufnych stron.
-
nie musisz używać zarówno meta robotów, jak i X-robots-tag na tej samej stronie – byłoby to zbędne.
Ucz się dalej
- ,txt
- X-Robots-Tag: prosta alternatywa dla robotów .txt i Meta Tag
- kontrolowanie crawlerów wyszukiwarek w celu lepszej indeksacji i rankingów
- roboty Meta Tag i X-Robots-Tag Specyfikacja nagłówka HTTP
Wykorzystaj swoje umiejętności
Moz Pro pozwala na uruchamianie indeksów, badania i raportowanie rankingu słów kluczowych oraz śledzenie wydajności SEO witryny, w tym jej dostępności, w czasie. Spróbuj > >