Wat zijn robot meta tags?
Robots meta directives (soms “meta tags” genoemd) zijn stukjes code die crawlers instructies geven voor het crawlen of indexeren van inhoud van webpagina ‘ s. Terwijl robots.txt file directives geven bots suggesties voor het crawlen van pagina ‘ s van een website, robots meta directives bieden meer stevige instructies over het crawlen en indexeren van de inhoud van een pagina.,
Er zijn twee typen robots meta-richtlijnen: die welke deel uitmaken van de HTML-pagina (zoals de meta robotstag) en die welke de webserver als HTTP-headers verzendt (zoals x-robots-tag). Dezelfde parameters (dat wil zeggen de crawling-of indexeringsinstructies die een meta-tag geeft, zoals ” noindex “en” nofollow ” in het bovenstaande voorbeeld) kunnen worden gebruikt met zowel meta robots als de x-robots-tag; wat verschilt is hoe deze parameters worden gecommuniceerd naar crawlers.,
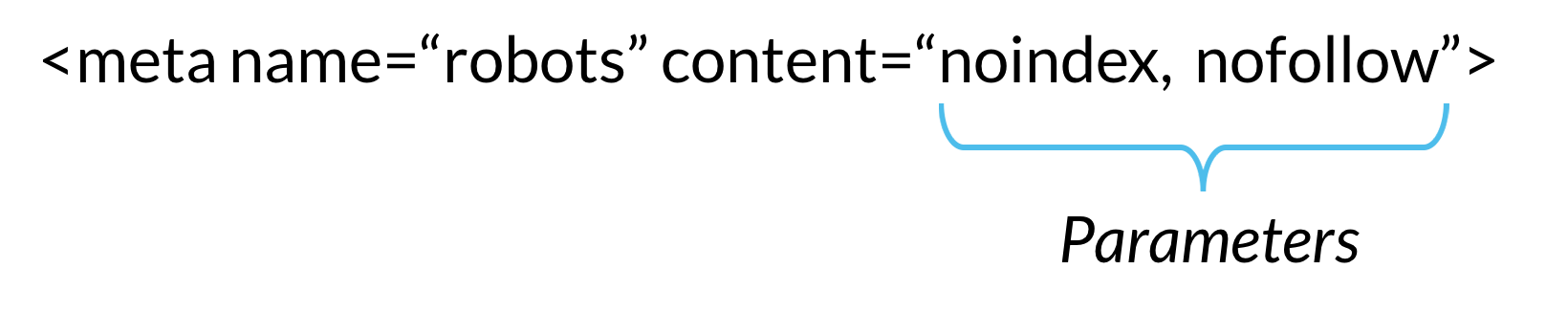
Meta-richtlijnen geven crawlers instructies over het crawlen en indexeren van informatie die ze vinden op een specifieke webpagina. Als deze richtlijnen worden ontdekt door bots, hun parameters dienen als sterke suggesties voor crawler indexatie gedrag. Maar zoals met robots.TXT-bestanden, crawlers hoeven uw meta-richtlijnen niet te volgen, dus het is een veilige gok dat sommige kwaadaardige webrobots uw richtlijnen zullen negeren.,
Hieronder staan de parameters die zoekmachine crawlers begrijpen en volgen wanneer ze gebruikt worden in robots meta directives. De parameters zijn niet hoofdlettergevoelig, maar merk wel op dat het mogelijk is dat sommige zoekmachines slechts een subset van deze parameters volgen of sommige richtlijnen iets anders behandelen.
indexatie-controlerende parameters:
-
Noindex: vertelt een zoekmachine een pagina niet te indexeren.
-
Index: vertelt een zoekmachine om een pagina te indexeren. Merk op dat je deze meta tag niet hoeft toe te voegen; Het is de standaard.,
-
volg: zelfs als de pagina niet geïndexeerd is, moet de crawler alle links op een pagina volgen en equity doorgeven aan de gelinkte pagina ‘ s.
-
Nofollow: vertelt een crawler geen links op een pagina te volgen of een link equity door te geven.
-
Noimageindex: vertelt een crawler geen afbeeldingen op een pagina te indexeren.
-
None: gelijk aan het gelijktijdig gebruik van de tags noindex en nofollow.
-
Noarchive: zoekmachines mogen geen link in de cache naar deze pagina tonen op een SERP.,
-
Nocache: hetzelfde als noarchive, maar alleen gebruikt door Internet Explorer en Firefox.
-
Nosnippet: vertelt een zoekmachine om geen fragment van deze pagina (d.w.z. metabeschrijving) van deze pagina op een SERP te tonen.
-
Noodyp / noydir: voorkomt dat zoekmachines de DMOZ-beschrijving van een pagina gebruiken als SERP-fragment voor deze pagina. Echter, DMOZ werd met pensioen in het begin van 2017, waardoor deze tag verouderd.
-
Unavailable_after: zoekmachines moeten deze pagina niet langer indexeren na een bepaalde datum.,
Types van robots meta directives
Er zijn twee hoofdtypes van robots meta directives: de meta robots tag en de x-robots-tag. Elke parameter die kan worden gebruikt in een meta robots tag kan ook worden gespecificeerd in een x-robots-tag.
We zullen het hebben over de meta robots en x-robots tag richtlijnen hieronder.,pagina ‘ s HTML-code en wordt als code-elementen in een webpagina is <head> sectie:
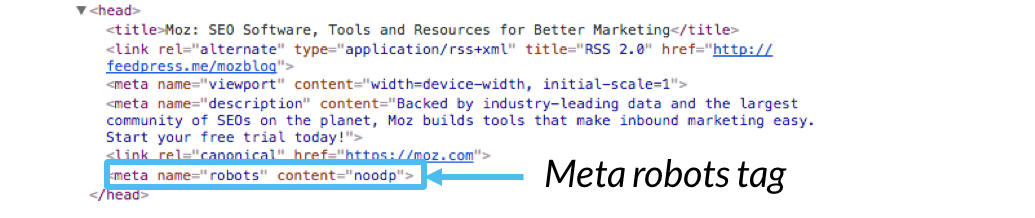
voorbeeld Code:
<pre><meta name=”robots” content=””></pre>
Terwijl de algemene <meta name="robots" content=""> – tag is standaard, kunt u ook de richtlijnen voor specifieke crawlers door het vervangen van de “robots”, met de naam van een specifieke user-agent., Bijvoorbeeld, om een richtlijn specifiek op Googlebot te richten, zou u de volgende code gebruiken:
<meta name="googlebot" content="">
wilt u meer dan één richtlijn op een pagina gebruiken? Zolang ze zijn gericht op dezelfde “robot” (user-agent), meerdere richtlijnen kunnen worden opgenomen in een meta – richtlijn-gewoon scheiden ze door komma ‘ s. Hier is een voorbeeld:
<meta name="robots" content="noimageindex, nofollow, nosnippet">
deze tag zou robots vertellen om geen van de afbeeldingen op een pagina te indexeren, geen van de links te volgen, of een fragment van de pagina te tonen wanneer het op een SERP verschijnt.,
als u verschillende meta robots tag directives gebruikt voor verschillende search user-agents, moet u aparte tags gebruiken voor elke bot.
X-robots-tag
terwijl de meta robots-tag u de mogelijkheid biedt om het indexeringsgedrag op paginaniveau te controleren, kan de x-robots-tag worden opgenomen als onderdeel van de HTTP-header om de indexering van een pagina als geheel te beheren, evenals zeer specifieke elementen van een pagina.,
hoewel u de x-robots-tag kunt gebruiken om dezelfde indexeringsrichtlijnen uit te voeren als meta robots, biedt de x-robots-tag-richtlijn aanzienlijk meer flexibiliteit en functionaliteit dan de meta robots-tag niet. Specifiek, de x-robots staat het gebruik van reguliere expressies, het uitvoeren van crawl richtlijnen op niet-HTML-bestanden, en het toepassen van parameters op een globaal niveau.
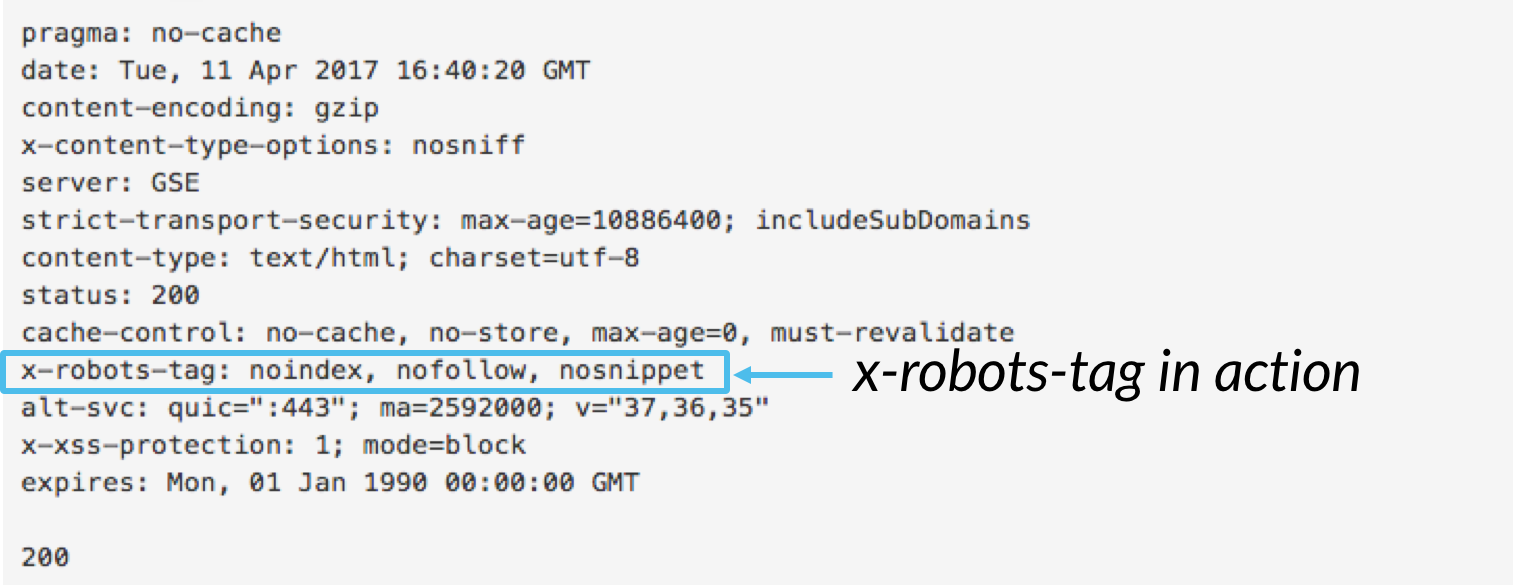
om de x-robots-tag te gebruiken, moet u toegang hebben tot de header van uw website .php, .htaccess, of server toegangsbestand., Voeg van daaruit de x-robots-tag-markup van uw specifieke serverconfiguratie toe, inclusief eventuele parameters. Dit artikel geeft een aantal grote voorbeelden van hoe X-robots-tag markup eruit ziet als je een van deze drie configuraties gebruikt.,Hier zijn een paar use cases waarom zou u gebruik maken van het x-robots-tag:
-
het Beheersen van de indexering van de inhoud niet geschreven in HTML (zoals flash of video)
-
het Blokkeren van de indexatie van een bepaald element van een pagina (zoals een afbeelding of video), maar niet van de hele pagina zelf
-
het Beheersen van indexatie als u geen toegang hebt tot een pagina in de HTML-code (in het bijzonder op de <kop> – gedeelte) of als je site gebruik maakt van een global header die niet kan worden gewijzigd
-
het Toevoegen van regels of een pagina moet worden geïndexeerd (ex., Als een gebruiker meer dan 20 keer commentaar heeft gegeven, indexeer dan zijn profielpagina)
SEO best practices with robots meta directives
-
alle Meta directives (robots of anderszins) worden ontdekt wanneer een URL wordt gekropen. Dit betekent dat als een robots.txt bestand staat de URL niet toe om te crawlen, elke meta directive op een pagina (ofwel in de HTML of de HTTP header) zal niet worden gezien en zal effectief worden genegeerd.
-
in de meeste gevallen moet het gebruik van een meta robots tag met parameters “noindex, follow” worden gebruikt als een manier om crawling of indexatie te beperken in plaats van robots te gebruiken.,txt-bestand staat niet toe.
-
Het is belangrijk op te merken dat kwaadaardige crawlers waarschijnlijk meta-richtlijnen volledig negeren en als zodanig is dit protocol geen goed beveiligingsmechanisme. Als u privégegevens hebt die u niet openbaar doorzoekbaar wilt maken, kiest u voor een veiliger aanpak, zoals wachtwoordbeveiliging, om te voorkomen dat bezoekers vertrouwelijke pagina ‘ s bekijken.
-
u hoeft niet zowel meta robots als de x-robots-tag op dezelfde pagina te gebruiken – dit zou overbodig zijn.
blijf
- Robots leren.,txt
- X-Robots-Tag: een eenvoudig alternatief voor Robots .txt en Meta Tag
- Controlling Search Engine Crawlers for Better Indexation and Rankings
- Robots meta Tag and X-Robots-Tag HTTP Header Specifications
Put your skills to work
met Moz Pro kunt u crawls uitvoeren, onderzoek doen en rapporteren over trefwoord ranking, en de SEO-prestaties van uw site volgen, inclusief de toegankelijkheid ervan, in de loop van de tijd. Probeer het >>