Cosa sono i meta tag robot?
Le meta direttive dei robot (a volte chiamate “meta tag”) sono pezzi di codice che forniscono istruzioni ai crawler su come eseguire la scansione o indicizzare il contenuto della pagina Web. Mentre i robot.le direttive sui file txt forniscono suggerimenti ai bot su come eseguire la scansione delle pagine di un sito Web, le direttive meta dei robot forniscono istruzioni più precise su come eseguire la scansione e indicizzare il contenuto di una pagina.,
Esistono due tipi di meta direttive robot: quelle che fanno parte della pagina HTML (come il meta robotstag) e quelle che il server web invia come intestazioni HTTP (come x-robots-tag). Gli stessi parametri (cioè le istruzioni di scansione o indicizzazione fornite da un meta tag, come “noindex” e “nofollow” nell’esempio precedente) possono essere utilizzati sia con i meta robot che con il tag x-robots; ciò che differisce è il modo in cui questi parametri vengono comunicati ai crawler.,
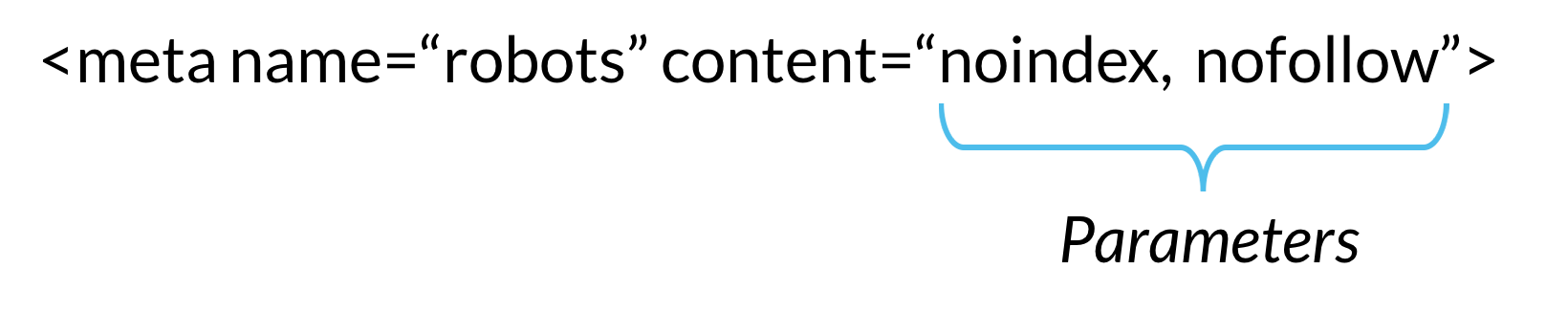
Le meta direttive forniscono ai crawler istruzioni su come eseguire la scansione e indicizzare le informazioni che trovano su una pagina web specifica. Se queste direttive vengono scoperte dai bot, i loro parametri fungono da forti suggerimenti per il comportamento di indicizzazione del crawler. Ma come con i robot.i file txt, i crawler non devono seguire le tue meta direttive, quindi è una scommessa sicura che alcuni robot web dannosi ignoreranno le tue direttive.,
Di seguito sono riportati i parametri che i crawler dei motori di ricerca capiscono e seguono quando vengono utilizzati nelle meta direttive dei robot. I parametri non sono case-sensitive, ma si noti che è possibile che alcuni motori di ricerca possano seguire solo un sottoinsieme di questi parametri o possano trattare alcune direttive in modo leggermente diverso.
Parametri di controllo dell’indicizzazione:
-
Noindex: indica a un motore di ricerca di non indicizzare una pagina.
-
Indice: indica a un motore di ricerca di indicizzare una pagina. Si noti che non è necessario aggiungere questo meta tag; è l’impostazione predefinita.,
-
Follow: Anche se la pagina non è indicizzata, il crawler dovrebbe seguire tutti i link di una pagina e passare equity alle pagine collegate.
-
Nofollow: dice a un crawler di non seguire alcun link su una pagina o passare lungo qualsiasi link equity.
-
Noimageindex: indica a un crawler di non indicizzare le immagini su una pagina.
-
None: equivalente all’utilizzo simultaneo di entrambi i tag noindex e nofollow.
-
Noarchive: i motori di ricerca non dovrebbero mostrare un link memorizzato nella cache a questa pagina su una SERP.,
-
Nocache: come noarchive, ma utilizzato solo da Internet Explorer e Firefox.
-
Nosnippet: indica a un motore di ricerca di non mostrare un frammento di questa pagina (cioè una meta descrizione) di questa pagina su una SERP.
-
Noodyp / noydir : impedisce ai motori di ricerca di utilizzare la descrizione DMOZ di una pagina come snippet SERP per questa pagina. Tuttavia, DMOZ è stato ritirato all’inizio del 2017, rendendo questo tag obsoleto.
-
Unavailable_after: i motori di ricerca non dovrebbero più indicizzare questa pagina dopo una data particolare.,
Tipi di meta direttive robot
Esistono due tipi principali di meta direttive robot: il tag meta robot e il tag x-robots. Qualsiasi parametro che può essere utilizzato in un tag meta robots può anche essere specificato in un x-robots-tag.
Parleremo di entrambe le direttive di tag meta robots e x-robots di seguito.,pagina di codice HTML che viene visualizzato come codice di elementi all’interno di una pagina web <head> sezione:
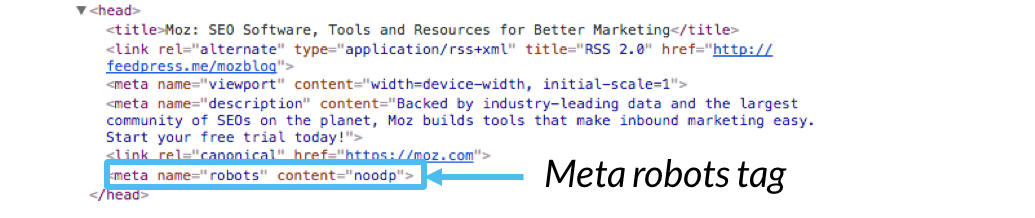
Codice di esempio:
<pre><meta name=”robots” content=””></pre>
Mentre il generale <meta name="robots" content=""> tag è standard, è possibile anche fornire direttive specifiche crawler, sostituendo il “robot” con il nome di uno specifico user-agent., Ad esempio, per indirizzare una direttiva specificamente a Googlebot, dovresti usare il seguente codice:
<meta name="googlebot" content="">
Vuoi usare più di una direttiva su una pagina? Finché sono mirati allo stesso” robot ” (user-agent), più direttive possono essere incluse in una meta direttiva – basta separarle da virgole. Ecco un esempio:
<meta name="robots" content="noimageindex, nofollow, nosnippet">
Questo tag direbbe ai robot di non indicizzare nessuna delle immagini su una pagina, seguire uno qualsiasi dei collegamenti o mostrare un frammento della pagina quando appare su una SERP.,
Se si utilizzano diverse direttive di tag meta robot per diversi user-agent di ricerca, è necessario utilizzare tag separati per ciascun bot.
X-robots-tag
Mentre il tag meta robots consente di controllare il comportamento di indicizzazione a livello di pagina, il tag x-robots può essere incluso come parte dell’intestazione HTTP per controllare l’indicizzazione di una pagina nel suo complesso, così come elementi molto specifici di una pagina.,
Mentre è possibile utilizzare x-robots-tag per eseguire tutte le stesse direttive di indicizzazione come meta robot, la direttiva x-robots-tag offre significativamente più flessibilità e funzionalità che il tag meta robot non lo fa. Nello specifico, x-robots consente l’uso di espressioni regolari, l’esecuzione di direttive di scansione su file non HTML e l’applicazione di parametri a livello globale.
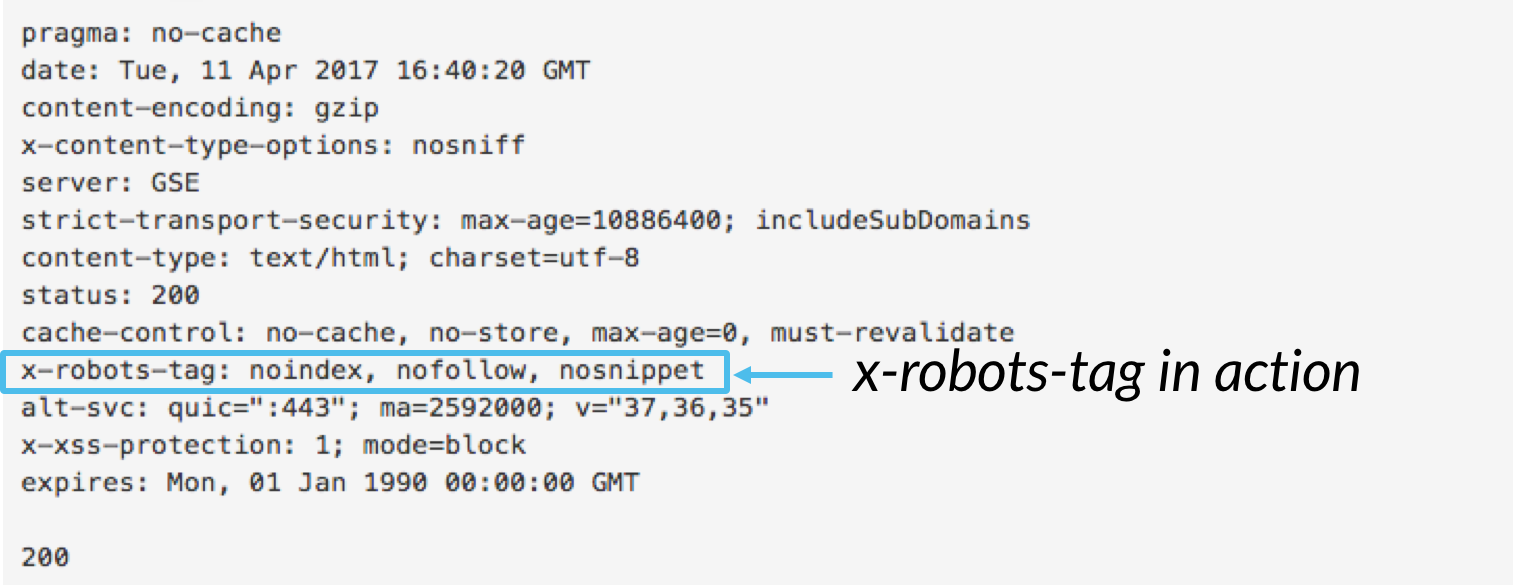
Per utilizzare x-robots-tag, devi avere accesso all’intestazione del tuo sito web .PHP, .htaccess, o file di accesso al server., Da lì, aggiungi il markup x-robots-tag della tua configurazione server specifica, inclusi tutti i parametri. Questo articolo fornisce alcuni grandi esempi di ciò che x-robots-tag markup si presenta come se si sta utilizzando una di queste tre configurazioni.,Qui ci sono alcuni casi di utilizzo per cui si potrebbe utilizzare l’x-robots-tag:
-
Controllare l’indicizzazione del contenuto non è scritto in HTML (come flash o video)
-
il Blocco dell’indicizzazione di un particolare elemento di una pagina (come un’immagine o un video), ma non di tutta la pagina
-
Controllare l’indicizzazione, se non si ha accesso a una pagina HTML (in particolare, per il <testa> sezione) o se il tuo sito utilizza un’intestazione (header) globale che non può essere modificato
-
l’Aggiunta di regole esistenza o meno di una pagina deve essere indicizzato (ex., Se un utente ha commentato più di 20 volte, indicizza la pagina del suo profilo)
SEO best practice with robots meta directives
-
Tutte le meta directives (robot o altro) vengono scoperte quando viene eseguito il crawling di un URL. Ciò significa che se un robot.il file txt non consente all’URL di eseguire la scansione, qualsiasi meta direttiva su una pagina (nell’HTML o nell’intestazione HTTP) non verrà vista e verrà, in modo efficace, ignorata.
-
Nella maggior parte dei casi, l’uso di un tag meta robot con i parametri “noindex, follow” dovrebbe essere impiegato come un modo per limitare la scansione o l’indicizzazione invece di usare i robot.,il file txt non consente.
-
È importante notare che è probabile che i crawler dannosi ignorino completamente le meta direttive e, come tale, questo protocollo non costituisce un buon meccanismo di sicurezza. Se si dispone di informazioni private che non si desidera rendere pubblicamente ricercabili, scegliere un approccio più sicuro, come la protezione con password, per impedire ai visitatori di visualizzare le pagine riservate.
-
Non è necessario utilizzare entrambi i meta robot e il tag x-robots sulla stessa pagina: farlo sarebbe ridondante.
Continua ad imparare
- Robot.,txt
- X-Robots-Tag: Una semplice alternativa per i robot .txt e Meta Tag
- Controllo dei crawler dei motori di ricerca per una migliore indicizzazione e classifiche
- Robot Meta Tag e X-Robots-Tag HTTP Header Specifications
Metti al lavoro le tue abilità
Moz Pro ti consente di eseguire crawls, ricercare e riferire sul ranking delle parole chiave e monitorare le prestazioni SEO del tuo Prova >>