Que sont les balises meta robot?
Les méta-directives Robots (parfois appelées « balises meta ») sont des morceaux de code qui fournissent des instructions aux robots d’exploration pour analyser ou indexer le contenu d’une page Web. Alors que les robots.les directives de fichier txt donnent aux robots des suggestions sur la façon d’explorer les pages d’un site Web, les directives meta de robots fournissent des instructions plus fermes sur la façon d’explorer et d’indexer le contenu d’une page.,
Il existe deux types de directives robots: celles qui font partie de la page HTML (comme le meta robotstag) et celles que le serveur Web envoie sous forme d’en-têtes HTTP (comme x-robots-tag). Les mêmes paramètres (c’est-à-dire les instructions d’exploration ou d’indexation fournies par une balise meta, telles que « noindex » et « nofollow » dans l’exemple ci-dessus) peuvent être utilisés avec les robots meta et la balise x-robots; ce qui diffère, c’est la façon dont ces paramètres sont communiqués aux robots.,
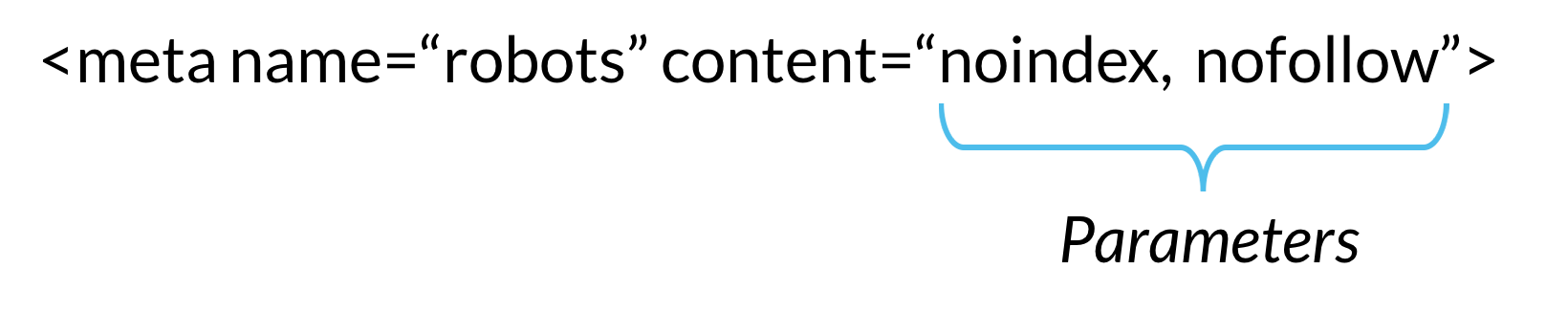
Meta directives donnent robots des instructions sur la façon d’analyser et d’indexer les informations qu’ils trouvent sur une page web spécifique. Si ces directives sont découvertes par des robots, leurs paramètres servent de suggestions fortes pour le comportement d’indexation du robot. Mais comme avec les robots.les fichiers txt, les robots d’exploration n’ont pas à suivre vos méta-directives, il y a donc fort à parier que certains robots Web malveillants ignoreront vos directives.,
Voici les paramètres que les robots d’exploration des moteurs de recherche comprennent et suivent lorsqu’ils sont utilisés dans les directives méta des robots. Les paramètres ne sont pas sensibles à la casse, mais notez qu’il est possible que certains moteurs de recherche ne suivent qu’un sous-ensemble de ces paramètres ou traitent certaines directives légèrement différemment.
Indexation-contrôle des paramètres:
-
Noindex: Indique à un moteur de recherche de ne pas indexer une page.
-
Index: Indique un moteur de recherche pour indexer une page. Notez que vous n’avez pas besoin d’ajouter cette balise meta; c’est la valeur par défaut.,
-
Suivre: Même si la page n’est pas indexée, le robot d’exploration doit suivre tous les liens d’une page et transmettre equity aux pages liées.
-
Nofollow: Indique à un robot de ne suivre aucun lien sur une page ou de transmettre aucune équité de lien.
-
Noimageindex: Indique à un robot de ne pas indexer d’images sur une page.
-
None: Équivalent à l’utilisation simultanée des balises noindex et nofollow.
-
Noarchive: Les moteurs de recherche ne doivent pas afficher de lien mis en cache vers cette page sur un SERP.,
-
Nocache: Identique à noarchive, mais utilisé uniquement par Internet Explorer et Firefox.
-
Nosnippet: Indique à un moteur de recherche de ne pas afficher un extrait de cette page (c’est-à-dire une méta description) de cette page sur un SERP.
-
Noodyp / noydir : Empêche les moteurs de recherche d’utiliser la description DMOZ d’une page comme extrait de SERP pour cette page. Cependant, DMOZ a été retiré au début de 2017, rendant cette balise obsolète.
-
Unavailable_after: Les moteurs de recherche ne doivent plus indexer cette page après une date particulière.,
Types de meta robots directives
Il existe deux principaux types de meta robots directives: la balise meta robots et les x-robots-tag. Tout paramètre pouvant être utilisé dans une balise meta robots peut également être spécifié dans une balise x-robots.
Nous allons parler des directives de balises meta robots et x-robots ci-dessous.,page de code HTML et apparaît comme éléments de code dans une page web <head> section:
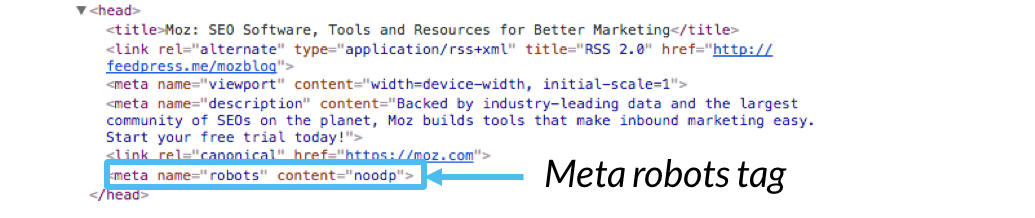
exemple de Code:
<avant><meta name= »robots » content= » »></pre>
Tandis que le <meta name="robots" content=""> balise est standard, vous pouvez également fournir des directives pour les robots d’indexation spécifiques en remplaçant les « robots » avec le nom du user-agent., Par exemple, pour cibler une directive spécifiquement à Googlebot, il vous suffit d’utiliser le code suivant:
<meta name="googlebot" content="">
vous Voulez utiliser plus d’une directive sur une page? Tant qu’elles sont ciblées sur le même « robot » (agent utilisateur), plusieurs directives peuvent être incluses dans une méta-directive – il suffit de les séparer par des virgules. Voici un exemple:
<meta name="robots" content="noimageindex, nofollow, nosnippet">
Cette balise indiquerait aux robots de ne pas indexer les images d’une page, de suivre l’un des liens ou d’afficher un extrait de la page lorsqu’il apparaît sur un SERP.,
Si vous utilisez différentes directives de balises meta robots pour différents agents utilisateurs de recherche, vous devrez utiliser des balises distinctes pour chaque bot.
X-robots-tag
Alors que la balise meta robots vous permet de contrôler le comportement d’indexation au niveau de la page, la balise x-robots-tag peut être incluse dans l’en-tête HTTP pour contrôler l’indexation d’une page dans son ensemble, ainsi que des éléments très spécifiques d’une page.,
Bien que vous puissiez utiliser la balise x-robots pour exécuter toutes les mêmes directives d’indexation que les méta-robots, la directive x-robots-tag offre beaucoup plus de flexibilité et de fonctionnalités que la balise meta-robots. Plus précisément, les robots x permettent l’utilisation d’expressions régulières, l’exécution de directives d’exploration sur des fichiers non HTML et l’application de paramètres au niveau global.
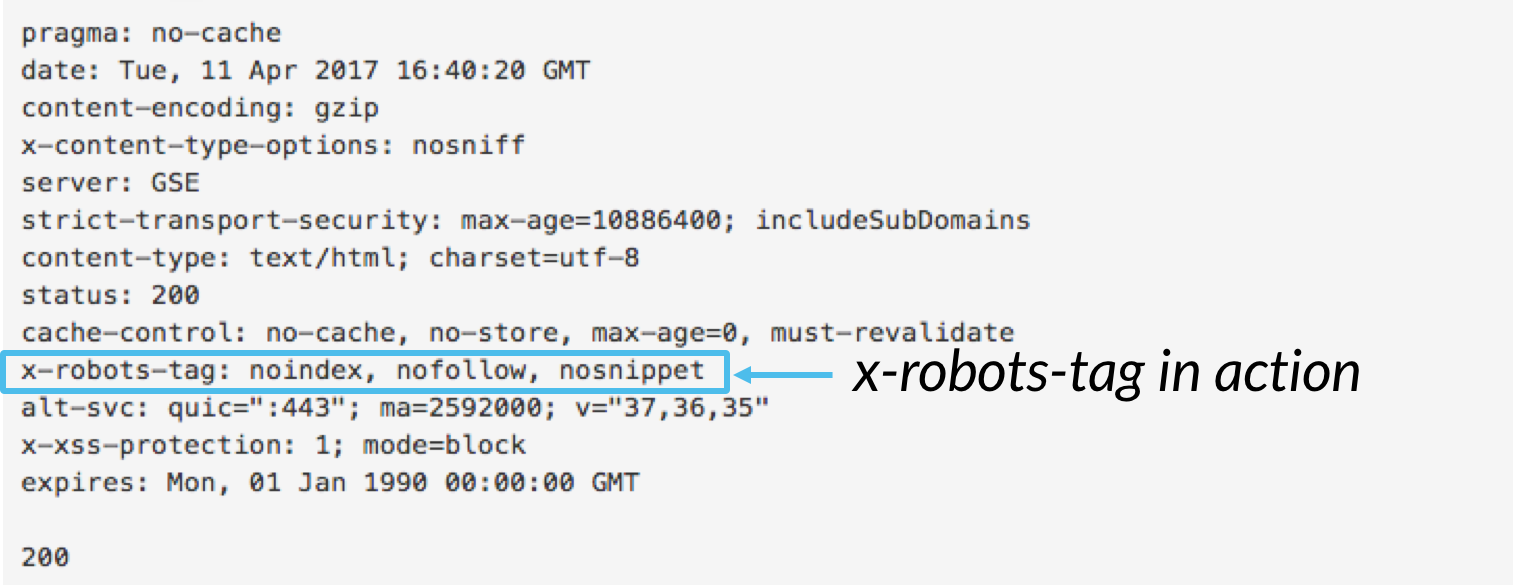
Pour utiliser la balise x-robots, vous devez avoir accès à l’en-tête de votre site Web .php, .htaccess, ou fichier d’accès au serveur., À partir de là, ajoutez le balisage x-robots-tag de votre configuration de serveur spécifique, y compris tous les paramètres. Cet article fournit quelques excellents exemples de ce à quoi ressemble le balisage x-robots-tag si vous utilisez l’une de ces trois configurations.,Voici quelques cas d’utilisation pour expliquer pourquoi vous pouvez utiliser la balise x-robots:
-
Contrôle de l’indexation de contenu non écrit en HTML (comme flash ou vidéo)
-
Blocage de l’indexation d’un élément particulier d’une page (comme une image ou une vidéo), mais pas de la page entière elle-même
-
Contrôle de l’indexation si »8c5a33b9b2″>head> section) ou si votre site utilise un en-tête global qui ne peut pas être modifié
-
En ajoutant des règles pour savoir si une page doit être indexée ou non (ex., Si un utilisateur a commenté plus de 20 fois, indexez sa page de profil)
Meilleures pratiques SEO avec les méta-directives robots
-
Toutes les méta-directives (robots ou autres) sont découvertes lorsqu’une URL est explorée. Cela signifie que si un des robots.le fichier txt interdit l’exploration de l’URL, toute directive méta sur une page (soit dans l’en-tête HTML ou HTTP) ne sera pas vue et sera, effectivement, ignorée.
-
Dans la plupart des cas, l’utilisation d’une balise meta robots avec les paramètres « noindex, follow » devrait être utilisée comme moyen de restreindre l’exploration ou l’indexation au lieu d’utiliser des robots.,le fichier txt interdit.
-
Il est important de noter que les robots d’exploration malveillants sont susceptibles d’ignorer complètement les méta-directives et, en tant que tel, ce protocole ne constitue pas un bon mécanisme de sécurité. Si vous avez des informations privées que vous ne souhaitez pas rendre publiques, choisissez une approche plus sécurisée, telle que la protection par mot de passe, pour empêcher les visiteurs de consulter des pages confidentielles.
-
Vous n’avez pas besoin d’utiliser à la fois des méta-robots et la balise x-robots sur la même page – cela serait redondant.
continuer à apprendre
- des Robots.,txt
- X-Robots-Tag: Une Alternative Simple Pour Les Robots .txt et Meta Tag
- Contrôler les robots des moteurs de recherche pour une meilleure indexation et un meilleur classement
- Robots Meta Tag et X-Robots-Tag HTTP Header Specifications
Mettez vos compétences au travail
Moz Pro vous permet d’exécuter des analyses, de rechercher et de rendre compte du classement Essayer >>