Support Vector Machine tai SVM on yksi suosituimmista Valvottu Oppiminen algoritmeja, joita käytetään Luokittelua sekä Regressio-ongelmia. Ensisijaisesti sitä kuitenkin käytetään koneoppimisen Luokitteluongelmiin.
tavoitteena SVM-algoritmi on luoda paras line tai päätöksen raja, että voi erottaa n-ulotteinen avaruus luokkiin niin, että voimme helposti laittaa uudet tiedot kohta oikeaan luokkaan tulevaisuudessa., Tätä parasta ratkaisurajaa kutsutaan hyperplaaniksi.
SVM valitsee hyperplanen luomisessa auttavat ääripisteet / vektorit. Näitä ääritapauksia kutsutaan tukivektoreiksi, ja siksi algoritmia kutsutaan Tukivektorikoneeksi. Harkitse alla kaavio, jossa on kaksi eri ryhmää, jotka on luokiteltu käyttäen päätöksen raja tai hyperplane:

Esimerkki: SVM voidaan ymmärtää esimerkiksi, että meillä on käytetään KNN-luokitin., Oletetaan, että näemme outo kissa, että on myös joitakin ominaisuuksia koiria, joten jos haluamme malli, joka voi tarkasti tunnistaa, onko se on kissa tai koira, niin tällainen malli voidaan luoda käyttämällä SVM-algoritmi. Koulutamme ensin mallimme, jossa on paljon kuvia kissoista ja koirista, jotta se voi oppia kissojen ja koirien eri ominaisuuksista, ja sitten testaamme sitä tällä oudolla otuksella. Joten koska tukivektori luo päätöksen rajan näiden kahden tiedon (kissa ja koira) ja valita äärimmäisiä tapauksia (tuki vektorit), se näkee äärimmäinen tapaus kissan ja koiran., Tukivektorien perusteella se luokittelee sen Kissaksi. Tarkastellaan alla olevan kaavion mukaisesti:
SVM-algoritmia voidaan käyttää Kasvojen tunnistus, kuvan luokittelu, tekstin luokittelu, jne.
Tyypit SVM
SVM voi olla kahdenlaisia:
- Lineaarinen SVM: Lineaarinen SVM käytetään lineaarisesti separoituvia tiedot, mikä tarkoittaa, että jos aineisto voidaan luokitella kahteen luokkaan käyttämällä yksittäinen suora viiva, sitten tällaisia tietoja kutsutaan kuin lineaarisesti separoituvia tiedot, ja luokittelija käytetään kutsutaan Lineaarinen SVM-luokittelija.,
- epälineaarista SVM: epälineaarista SVM käytetään ei-lineaarisesti erotetaan data, mikä tarkoittaa, että jos aineisto ei voida luokitella käyttämällä suora viiva, sitten tällaisia tietoja kutsutaan kuin ei-lineaarinen tiedot ja luokittelija käyttää sitä kutsutaan epälineaarista SVM-luokittelija.
Hyperplane ja Tukea Vektorit SVM-algoritmi:
Hyperplane: Ei voi olla useita rivejä/päätös rajoja erottelemaan luokat n-ulotteinen avaruus, mutta meidän täytyy löytää ulos paras päätös rajan, joka auttaa luokittelemaan tiedot pistettä. Tämä paras raja tunnetaan SVM: n hyperplaneena.,
mitat hyperplane riippuvat ominaisuudet läsnä-datajoukon, joka tarkoittaa sitä, että jos on 2 ominaisuuksia (kuten esitetty kuvassa), sitten hyperplane tulee olla suora viiva. Ja jos ominaisuuksia on 3, hyperplane on 2-ulotteinen taso.
me luomme aina hyperplanen, jolla on maksimimarginaali eli maksimimatka datapisteiden välillä.
Tukea Vektorit:
tiedot pistettä tai vektorit, jotka ovat lähimpänä hyperplane ja joka vaikuttaa asemaan hyperplane ovat kutsutaan kuin Tuki Vektori., Koska nämä vektorit tukevat hyperplaania, niin sitä kutsutaan Tukivektoriksi.
miten SVM vaikuttaa?
Lineaarinen SVM:
työ-SVM-algoritmi voidaan ymmärtää esimerkin avulla. Oletetaan, että meillä on dataset, jossa on kaksi tagia (vihreä ja sininen), ja datasetissa on kaksi ominaisuutta x1 ja x2. Haluamme luokittelijan, joka voi luokitella koordinaattiparin (x1, x2) joko vihreäksi tai siniseksi. Harkitse alla kuva:
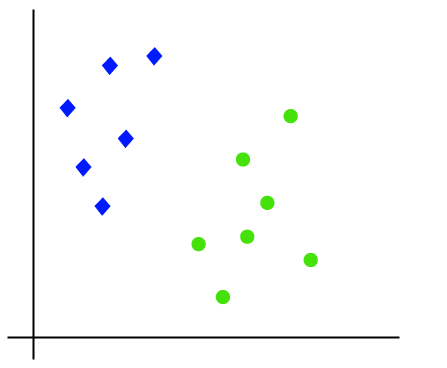
Niin, koska se on 2-d tilaa, joten vain käyttämällä suoraa linjaa, voimme helposti erottaa nämä kaksi luokkaa., Mutta voi olla useita linjoja, jotka voivat erottaa nämä luokat. Harkitse alla kuva:
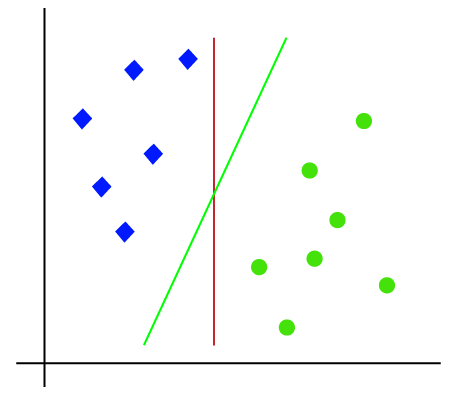
Näin ollen SVM-algoritmi auttaa löytää paras line tai päätös rajan; tämä paras raja tai alue, kutsutaan hyperplane. SVM: n algoritmi löytää rivien lähimmän pisteen molemmista luokista. Näitä kohtia kutsutaan tukivektoreiksi. Vektorien ja hyperplanen välistä etäisyyttä kutsutaan marginaaliksi. SVM: n tavoitteena on maksimoida tämä marginaali. Hyperplaneetta, jolla on suurin marginaali, kutsutaan optimaaliseksi hyperplaneksi.,

epälineaarista SVM:
Jos tiedot on lineaarisesti järjestetty, niin voimme erottaa sen käyttämällä suora viiva, mutta ei-lineaarisia tietoja, emme voi piirtää yksi suora viiva. Harkitse alla kuva:
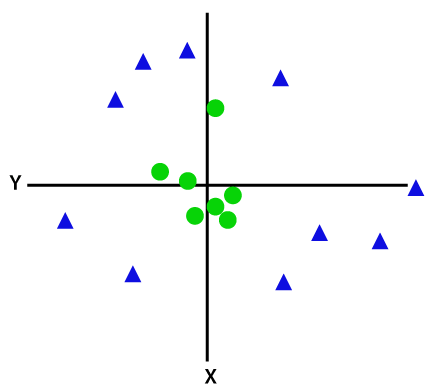
sitten erottaa nämä tiedot pistettä, meidän täytyy lisätä vielä yksi ulottuvuus. Lineaariseen dataan olemme käyttäneet kahta ulottuvuutta x ja y, joten epälineaariseen dataan lisäämme kolmannen ulottuvuuden z., Se voidaan laskea seuraavasti:
z=x2 +y2
lisäämällä kolmas ulottuvuus, näyte tilaa tulee alla kuva:
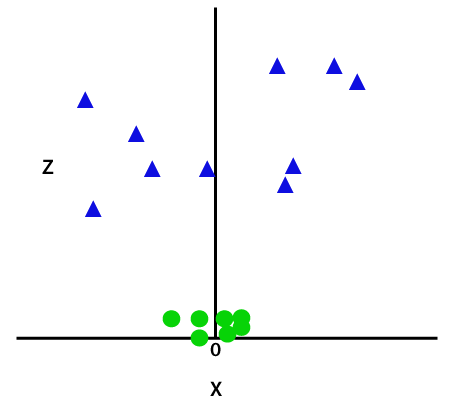
Joten nyt, SVM jakaa aineistot luokkiin seuraavalla tavalla. Harkitse alla kuva:
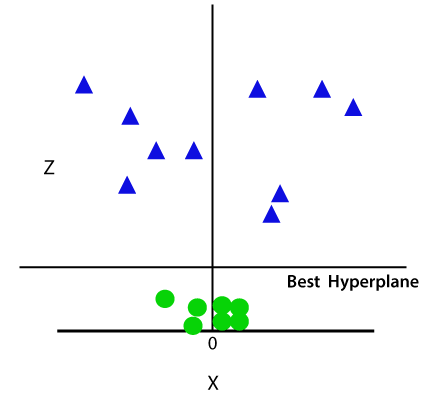
Koska olemme 3-d Avaruudessa, joten se etsii kuin yhdensuuntainen x-akselin kanssa. Jos me muuntaa sen 2D-avaruudessa z=1, Niin se tulee seuraavasti:
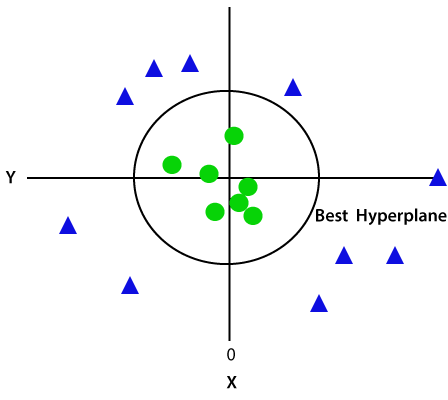
joten saamme ympärysmitta säde 1 Jos ei-lineaarinen data.,
Python Täytäntöönpano Support Vector Machine
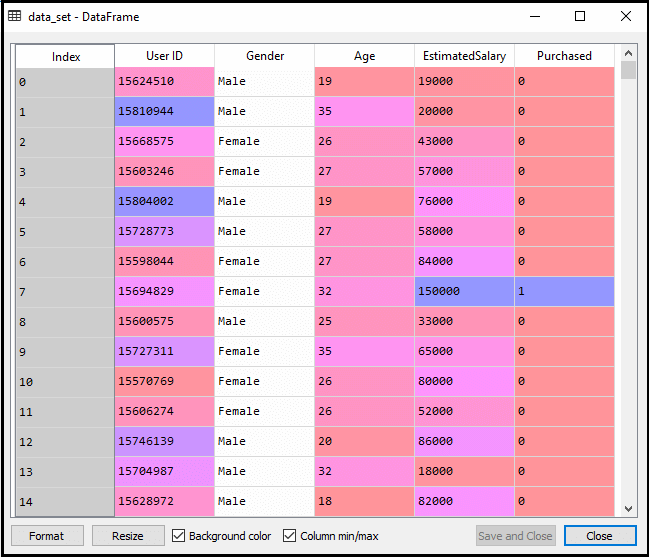
Nyt toteutamme SVM-algoritmia käyttäen Python. Tässä käytämme samaa aineistoa user_data, jota olemme käyttäneet logistisessa regressiossa ja KNN-luokituksessa.
- tietojen esikäsittelyvaihe
kunnes tietojen esikäsittelyvaihe, koodi pysyy samana. Alla on koodi:
edellä olevan koodin suorittamisen jälkeen esikäsittelemme tiedot., Koodi antaa tietoaineiston:
skaalattu lähtö testi setti on:
Sopiva SVM-luokittelija koulutuksen sarja:
Nyt koulutus on asennettu SVM-luokittelija. Luodaksemme SVM-luokittajan tuomme SVC-luokan Sklearnista.svm-kirjasto. Alla on koodi se:
edellä koodi, olemme käyttäneet kernel=’linear’, kuten täällä olemme luomassa SVM varten lineaarisesti separoituvia tiedot. Voimme kuitenkin muuttaa sitä epälineaariseen dataan., Ja sitten me asentaa luokitin koulutuksen aineisto(x_train, y_train)
tuloksena on:
mallin suorituskykyä voidaan muuttaa muuttamalla arvo C(Laillistaminen tekijä), gamma -, ja ydin.
- Ennustaminen testin tulos:
Nyt, me ennustaa lähtö testi. Tätä varten luomme uuden vektorin y_pred. Alla on koodi se:
saatuaan y_pred vektori, voimme verrata tulosta y_pred ja y_test tarkistaa ero todellisen arvon ja ennustetun arvon.,
Lähtö: Alla on tuotoksen ennustamiseen testi sarja:

- Luoda confusion matrix:
Nyt näemme suorituskykyä SVM-luokittelija, että kuinka monta virheelliset ennusteet ovat siellä verrattuna Logistinen regressio luokittelija. Hämmennysmatriisin luomiseksi on tuotava sklearnin kirjaston confusion_matrix-funktio. Tuomisen jälkeen toiminto, kutsumme sitä käyttämällä uutta muuttujan cm. Toiminto vaatii kaksi parametrit, lähinnä y_true( todelliset arvot) ja y_pred (suunnattu arvo tuotto luokitin)., Alla on koodi se:
tuloksena on:
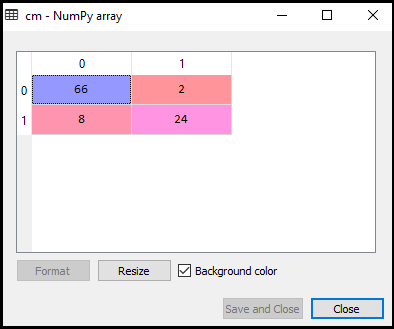
Kuten voimme nähdä edellä kuva, on 66+24= 90 oikea ennusteita ja 8+2= 10 oikea ennusteita. Siksi voimme sanoa, että SVM-mallimme parani verrattuna logistiseen regressiomalliin.,
- Visualisointiin koulutus asetettu tulos:
Nyt me visualisoida koulutus asetettu tulos, alla on koodi se:
tuloksena on:
suorittamalla edellä koodi, saamme tuloksen:
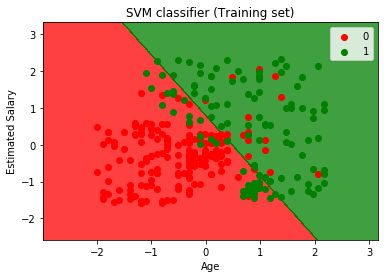
Kuten näemme, edellä tuotos on esiintyy samankaltaisia Logistinen regressio lähtö. Lähtö, saimme suoran linjan hyperplane, koska olemme käyttäneet lineaarinen ydin luokittaja. Ja olemme myös keskustelleet edellä, että 2d tilaa, hyperplane vuonna SVM on suora viiva.,
- Visualisointiin testin tulos:
tuloksena on:
suorittamalla edellä koodi, saamme tuloksen:
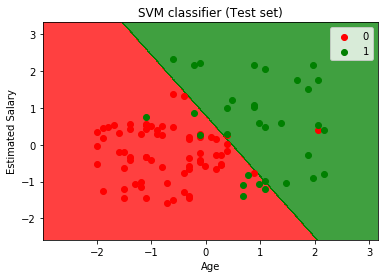
Kuten voimme nähdä edellä kuva, SVM-luokitin on jakaa käyttäjät kahteen alueet (Ostettu tai Ei-ostettu). Katumaasturin ostaneet käyttäjät ovat punaisella alueella red scatter-pisteillä. Ja käyttäjät, jotka eivät ostaneet katumaasturia, ovat vihreällä alueella green scatter-pisteillä. Hyperplane on jakanut nämä kaksi luokkaa ostettuihin eikä ostettuihin muuttujiin.