¿qué son las meta etiquetas de robots?
las meta directivas de Robots (a veces llamadas «meta tags») son piezas de código que proporcionan instrucciones a los rastreadores sobre cómo rastrear O indexar el contenido de las páginas web. Mientras que los robots.las directivas de archivos txt dan sugerencias de bots sobre cómo rastrear las páginas de un sitio web, las directivas meta de robots proporcionan instrucciones más firmes sobre cómo rastrear e indexar el contenido de una página.,
Hay dos tipos de meta directivas de robots: las que forman parte de la página HTML (como el meta robotstag) y las que el servidor Web envía como encabezados HTTP (como x-robots-tag). Los mismos parámetros (es decir, las instrucciones de rastreo o indexación que proporciona una etiqueta meta, como «noindex» y «nofollow» en el ejemplo anterior) se pueden usar tanto con meta robots como con la etiqueta X-robots; lo que difiere es cómo se comunican esos parámetros a los rastreadores.,
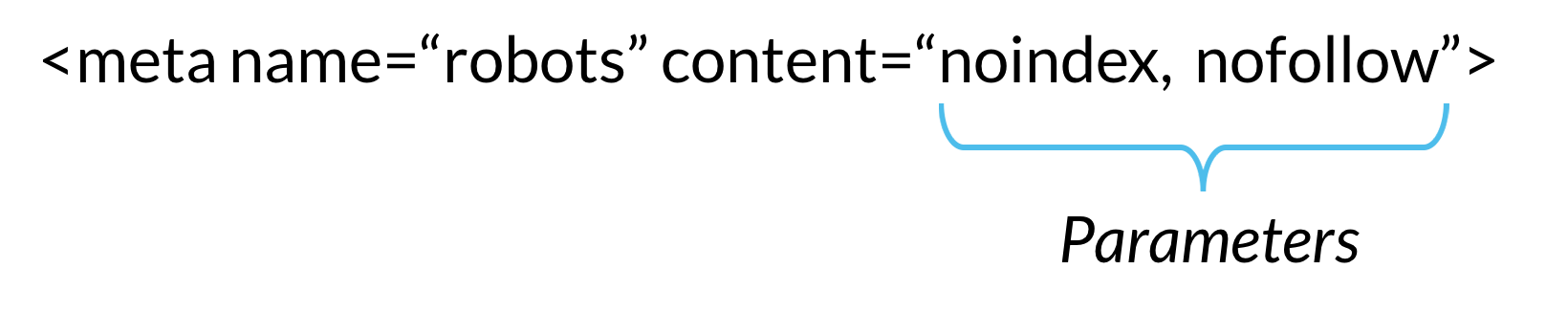
las Meta directivas dan instrucciones a los rastreadores sobre cómo rastrear e indexar la información que encuentran en una página web específica. Si estas directivas son descubiertas por bots, sus parámetros sirven como fuertes sugerencias para el comportamiento de indexación del rastreador. Pero como con los robots.archivos txt, rastreadores no tienen que seguir sus directivas meta, por lo que es una apuesta segura que algunos robots web maliciosos ignorarán sus directivas.,
a continuación se muestran los parámetros que los rastreadores de motores de búsqueda entienden y siguen cuando se usan en meta directivas de robots. Los parámetros no distinguen entre mayúsculas y minúsculas, pero tenga en cuenta que es posible que algunos motores de Búsqueda solo sigan un subconjunto de estos parámetros o traten algunas directivas de manera ligeramente diferente.
indexación-parámetros de control:
-
Noindex: indica a un motor de búsqueda que no indexe una página.
-
Index: indica a un motor de búsqueda que indexe una página. Ten en cuenta que no necesitas agregar esta meta etiqueta; es la predeterminada.,
-
Follow: incluso si la página no está indexada, el rastreador debe seguir todos los enlaces de una página y pasar equity a las páginas enlazadas.
-
Nofollow: le dice a un rastreador que no siga ningún enlace en una página ni pase ningún valor de enlace.
-
Noimageindex: le dice a un rastreador que no indexe ninguna imagen en una página.
-
None: equivalente a usar simultáneamente las etiquetas noindex y nofollow.
-
Noarchive: los motores de búsqueda no deben mostrar un enlace en caché a esta página en una SERP.,
-
Nocache: igual que noarchive, pero solo utilizado por Internet Explorer y Firefox.
-
Nosnippet: le dice a un motor de búsqueda que no muestre un fragmento de esta página (es decir, una meta descripción) de esta página en una SERP.
-
noodyp / noydir: evita que los motores de búsqueda utilicen la descripción del ODP de una página como fragmento de código SERP para esta página. Sin embargo, el ODP se retiró a principios de 2017, lo que hace que esta etiqueta sea obsoleta.
-
Unavailable_after: los motores de búsqueda ya no deben indexar esta página después de una fecha en particular.,
tipos de meta directivas de robots
Hay dos tipos principales de meta directivas de robots: la etiqueta meta robots y la etiqueta X-robots. Cualquier parámetro que se pueda usar en una etiqueta meta robots también se puede especificar en una etiqueta X-robots.
a continuación hablaremos de las directivas meta robots y X-robots tag.,HTML de la página de código y aparece como elementos de código dentro de una página web <head> sección:
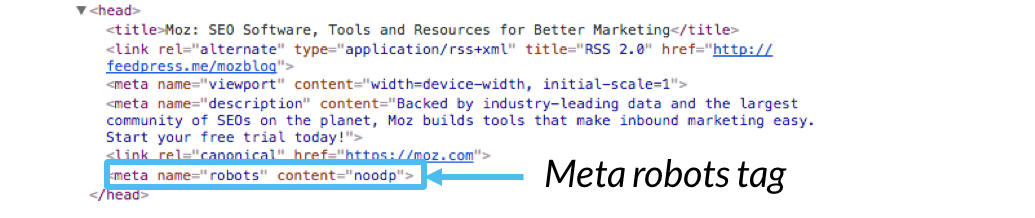
ejemplo de Código:
<pre><meta name=»robots» content=»»></pre>
Mientras que el general <meta name="robots" content=""> etiqueta estándar, también puede proporcionar directivas específicas rastreadores mediante la sustitución de los «robots» con el nombre de un agente de usuario., Por ejemplo, para dirigir una directiva específicamente al Googlebot, usarías el siguiente código:
<meta name="googlebot" content="">
¿quieres usar más de una directiva en una página? Siempre y cuando estén dirigidos al mismo «robot» (agente de usuario), se pueden incluir varias directivas en una meta directiva, solo sepárelas por comas. Este es un ejemplo:
<meta name="robots" content="noimageindex, nofollow, nosnippet">
Esta etiqueta indicaría a los robots que no indexen ninguna de las imágenes de una página, sigan ninguno de los enlaces o muestren un fragmento de la página cuando aparezca en una SERP.,
si está utilizando diferentes directivas de etiquetas de meta robots para diferentes agentes de usuario de búsqueda, deberá usar etiquetas separadas para cada bot.
X-robots-tag
mientras que la etiqueta meta robots le permite controlar el comportamiento de indexación a nivel de Página, la etiqueta x-robots-se puede incluir como parte del encabezado HTTP para controlar la indexación de una página en su conjunto, así como elementos muy específicos de una página.,
mientras que puede usar la etiqueta X-robots-tag para ejecutar todas las mismas directivas de indexación que los meta robots, la directiva X-robots-tag ofrece significativamente más flexibilidad y funcionalidad que la etiqueta meta robots. Específicamente, los X-robots permiten el uso de expresiones regulares, la ejecución de directivas de rastreo en archivos no HTML, y la aplicación de parámetros a nivel global.
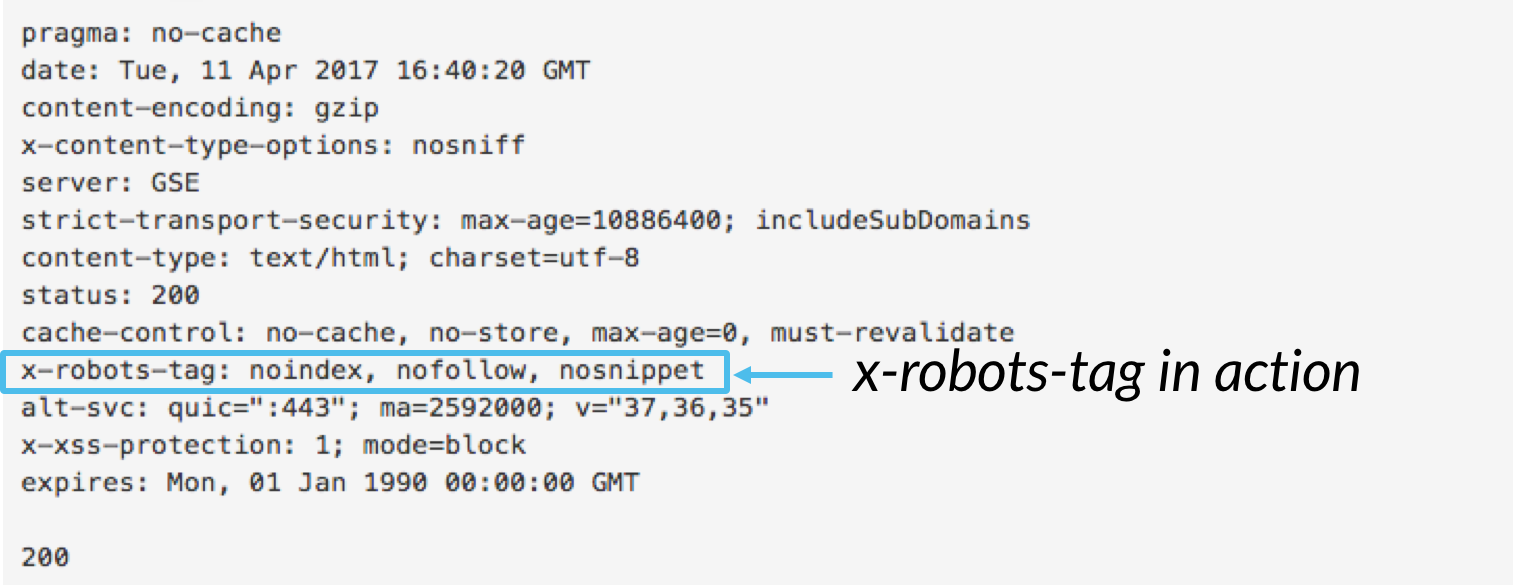
Para utilizar el x-robots-tag, usted necesitará tener acceso a su sitio web de cabecera .php, .htaccess, o archivo de acceso al servidor., Desde allí, agregue el marcado X-robots-tag de su configuración de servidor específica, incluidos los parámetros. Este artículo proporciona algunos grandes ejemplos de cómo se ve X-robots-tag markup si está utilizando cualquiera de estas tres configuraciones.,Estos son algunos casos de uso por los que puede emplear la etiqueta X-robots:
-
controlar la indexación de contenido no escrito en HTML (como flash o video)
-
bloquear la indexación de un elemento particular de una página (como una imagen o video), pero no de toda la página en SÍ
-
controlar la indexación si no tiene acceso al HTML de una página (específicamente, al <head> section) o si su sitio usa un encabezado global que no se puede cambiar
-
agregando reglas para si una página debe ser indexada o no (ej., Si un usuario ha comentado más de 20 veces, indexe su página de perfil)
las mejores prácticas de SEO con meta directivas de robots
-
todas las meta directivas (robots o de otro tipo) se descubren cuando se rastrea una URL. Esto significa que si un robots.el archivo txt no permite que la URL se rastree, cualquier meta directiva en una página (ya sea en el encabezado HTML o HTTP) no se verá y, efectivamente, se ignorará.
-
en la mayoría de los casos, el uso de una etiqueta meta robots con los parámetros «noindex, follow» debe emplearse como una forma de restringir el rastreo o la indexación en lugar de usar robots.,archivo txt no permite.
-
es importante tener en cuenta que es probable que los rastreadores maliciosos ignoren completamente las directivas meta y, como tal, este protocolo no es un buen mecanismo de seguridad. Si tienes información privada que no quieres que se pueda buscar públicamente, elige un enfoque más seguro, como la protección con contraseña, para evitar que los visitantes vean páginas confidenciales.
-
no es necesario utilizar tanto meta robots como X-robots-tag en la misma página, hacerlo sería redundante.
sigue aprendiendo
- Robots.,txt
- X-Robots-Tag: una alternativa Simple para Robots .txt y Meta Tag
- Control de rastreadores de motores de búsqueda para una mejor indexación y Clasificación
- Robots Meta Tag y X-Robots-Tag especificaciones de encabezado HTTP
ponga sus habilidades a trabajar
Moz Pro le permite ejecutar rastreos, investigar e informar sobre la clasificación de palabras clave, y rastrear el rendimiento SEO de su sitio, incluida su accesibilidad, a lo largo del tiempo. Pruébalo >>