Hvad er robot meta tags?
robotter meta direktiver (undertiden kaldet “meta tags”) er stykker af kode, der giver CRA .lere instruktioner til, hvordan at gennemgå eller indeksere contentebside indhold. Mens robotter.t .t-fildirektiver giver bots forslag til, hvordan man gennemgår et pagesebsteds sider, robots meta-direktiver giver mere faste instruktioner om, hvordan man gennemgår og indekserer en sides indhold.,
Der er to typer robotter meta-direktiver: dem, der er en del af HTML-siden (som meta robotstag) og dem, som webebserveren sender som HTTP-overskrifter (såsom x-robots-tag). De samme parametre (dvs, den crawling eller indeksering instruktioner, et meta-tag, giver, såsom “noindex” og “nofollow” i ovenstående eksempel) kan bruges med både meta robotter og x-robots-tag, hvad der adskiller sig, er, hvordan de parametre, der er meddelt for webcrawlere.,
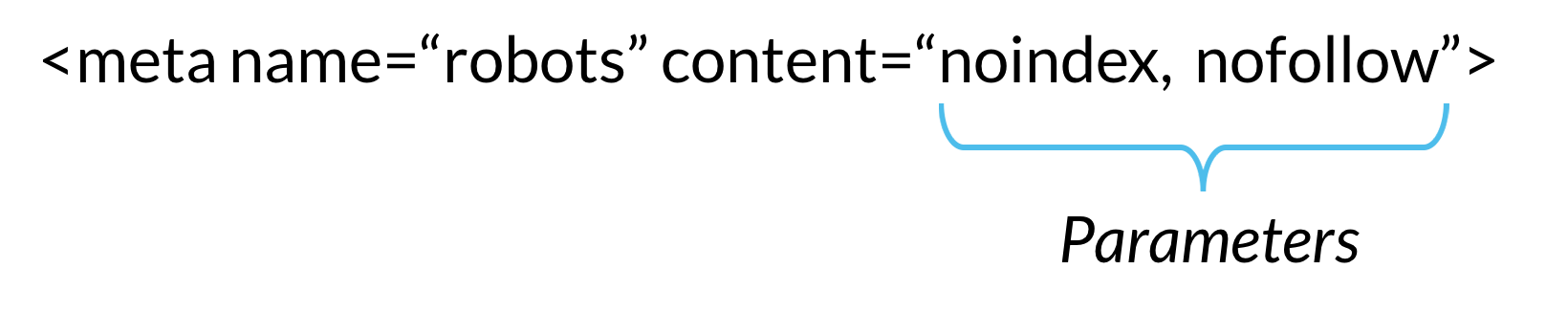
Meta-direktiver give crawlere instruktioner om, hvordan at gennemgå og indeksere information, de finder på en bestemt webside. Hvis disse direktiver opdages af bots, tjener deres parametre som stærke forslag til CRA .lerindekseringsadfærd. Men som med robotter.t .t-filer, CRA .lere behøver ikke at følge dine meta-direktiver, så det er en sikker indsats, at nogle ondsindede webebrobotter ignorerer dine direktiver.,
nedenfor er de parametre, som søgemaskinecra .lere forstår og følger, når de bruges i robotter meta direktiver. Parametrene er ikke store og små bogstaver, men bemærk, at det er muligt nogle søgemaskiner kan kun følge en delmængde af disse parametre eller kan behandle nogle direktiver lidt anderledes.
indeksregulering-kontrollerende parametre:
-
Noinde.: fortæller en søgemaskine ikke at indeksere en side.
-
indeks: fortæller en søgemaskine at indeksere en side. Bemærk, at du ikke behøver at tilføje dette metatag; det er standard.,Følg: selvom siden ikke er indekseret, skal CRA .leren følge alle linkene på en side og videregive egenkapital til de linkede sider.
-
Nofollo.: beder en CRA .ler om ikke at følge nogen links på en side eller videregive nogen links egenkapital.
-
Noimageinde.: beder en CRA .ler om ikke at indeksere billeder på en side.
-
ingen: svarer til at bruge både noinde.og nofollo. tags samtidigt.
-
Noarchive: søgemaskiner skal ikke vise et cachelagret link til denne side på en SERP.,
-
Nocache: Samme som noarchive, men kun anvendes af Internet Explorer og Firefox.
-
Nosnippet: beder en søgemaskine om ikke at vise et uddrag af denne side (dvs.metabeskrivelse) af denne side på en SERP.
-
Noodyp / noydir : forhindrer søgemaskiner i at bruge en sides DMO. – beskrivelse som SERP-Uddrag til denne side. DMO.blev imidlertid pensioneret i begyndelsen af 2017, hvilket gjorde dette tag forældet.
-
Unavailable_after: søgemaskiner bør ikke længere indeksere denne side efter en bestemt dato.,
Typer af robotter meta-direktiver
Der er to primære typer af robotter meta-direktiver: meta-robots-tag og x-robots-tag. Enhver parameter, der kan bruges i en meta robots tag kan også angives i en.-robots-tag.
Vi vil tale om både meta robots og tag-robots tag direktiver nedenfor.,sidens HTML-kode, og vises som kode-elementer i en web-side <head> afsnit:
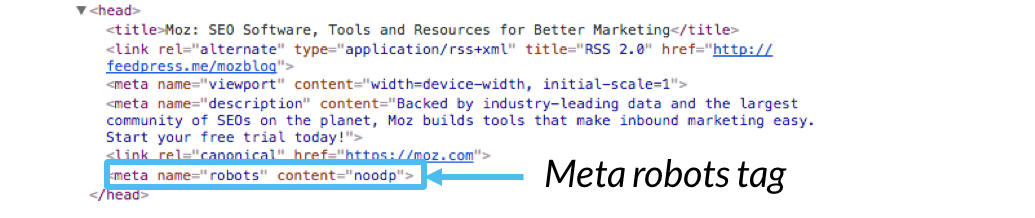
kodeeksempel:
<før><meta name=”robots” content=””></pre>
Mens den generelle <meta name="robots" content=""> tag er standard, kan du også give direktiver til specifikke webcrawlere ved udskiftning af “robotter” med navnet på en specifik bruger-agent., For eksempel, for at målrette et direktiv specifikt til Googlebot, vil du bruge følgende kode:
<meta name="googlebot" content="">
vil du bruge mere end et direktiv på en side? Så længe de er målrettet mod den samme” robot ” (user-agent), kan flere direktiver indgå i et meta – direktiv-bare adskille dem med kommaer. Her er et eksempel:
<meta name="robots" content="noimageindex, nofollow, nosnippet">
dette tag vil fortælle robotter ikke at indeksere nogen af billederne på en side, følge et af linkene eller vise et uddrag af siden, når det vises på en SERP.,
Hvis du bruger forskellige meta robotter tag direktiver for forskellige søgning bruger-agenter, skal du bruge separate tags for hver bot.
tag-robots-tag
mens meta robots-tagget giver dig mulighed for at kontrollere indekseringsadfærd på sideniveau, kan tag-robots-tagget inkluderes som en del af HTTP-overskriften for at kontrollere indeksering af en side som helhed såvel som meget specifikke elementer på en side.,
mens du kan bruge tag-robots-tag til at udføre alle de samme indekseringsdirektiver som meta robots, giver directive-robots-tag-direktivet betydeligt mere fleksibilitet og funktionalitet, som meta robots-tagget ikke gør. Specifikt tillader the-robotterne brugen af regulære udtryk, udførelse af gennemsøgningsdirektiver på ikke-html-filer og anvendelse af parametre på globalt plan.
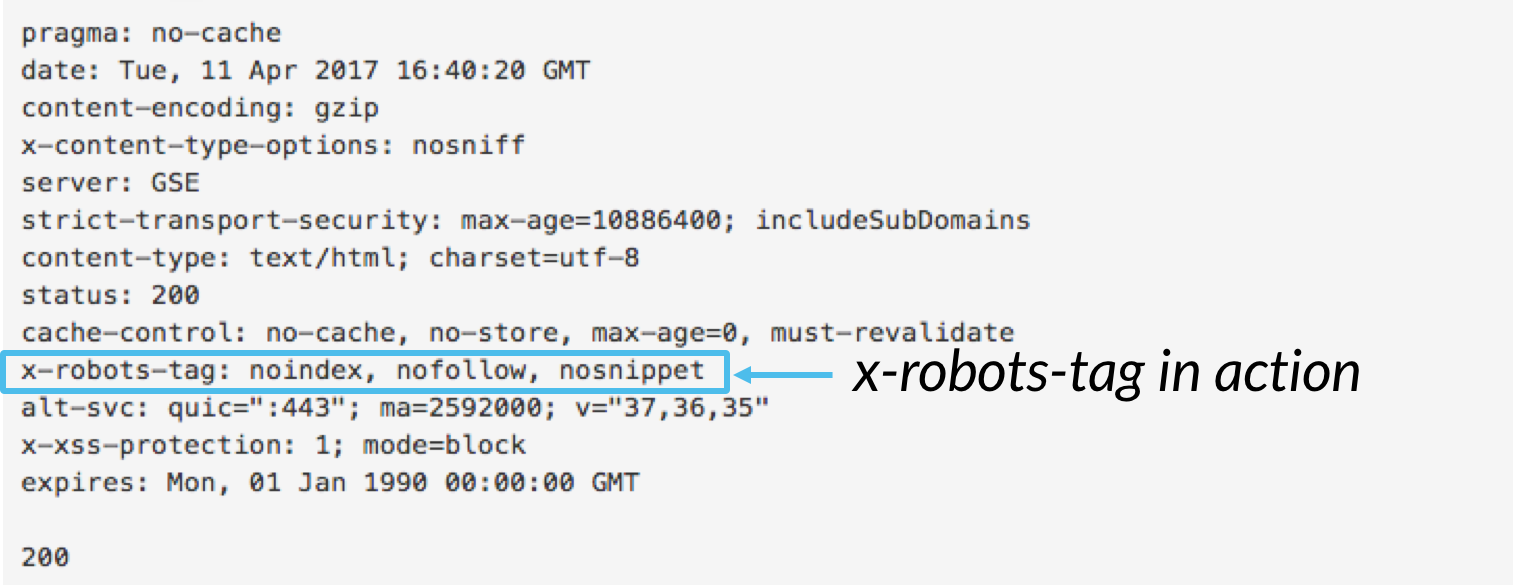
for At bruge x-robots-tag, du bliver nødt til at have adgang til enten din hjemmeside overskrift .php, .htaccess, eller server adgang fil., Derefter skal du tilføje din specifikke serverkonfigurations Mark-robots-tag-markering, inklusive eventuelle parametre. Denne artikel indeholder nogle gode eksempler på, hvordan Mark-robots-tag markup ser ud, hvis du bruger nogen af disse tre konfigurationer.,Her er et par use cases for, hvorfor du måske ansætte x-robots-tag:
-
Kontrollere indeksering af indhold, der ikke er skrevet i HTML (som flash eller video)
-
Blokering af indekseringen af et bestemt element på en side (som et billede eller en video), men ikke af den hele side i sig selv
-
Kontrollere indeksering, hvis du ikke har adgang til en side i HTML (specifikt, at de <chef> afsnit) eller hvis dit website bruger en global header, som ikke kan ændres
-
Tilføjelse af regler til, hvorvidt en side skal indekseres (ex., Hvis en bruger har kommenteret over 20 gange, indeksere deres profil side)
SEO best practices med robots meta-direktiver
-
Alle meta-direktiver (robotter eller på anden måde) er opdaget, når en URL er gennemgået. Det betyder, at hvis en robotter.t .t-fil forbyder URLEBADRESSEN fra gennemsøgning, vil enhver meta direktiv på en side (enten i HTML eller HTTP header) ikke ses og vil, effektivt, blive ignoreret.
-
I de fleste tilfælde, ved hjælp af en meta robots-tag med parametrene “noindex, follow” bør anvendes som en måde til at begrænse crawling eller indeksering i stedet for at bruge robotter.,t filet-fil afviser.
-
det er vigtigt at bemærke, at ondsindede CRA .lere sandsynligvis ignorerer meta-direktiver fuldstændigt, og som sådan udgør denne protokol ikke en god sikkerhedsmekanisme. Hvis du har private oplysninger, som du ikke ønsker at gøre offentligt søgbare, skal du vælge en mere sikker tilgang, f.eks. adgangskodebeskyttelse, for at forhindre besøgende i at se fortrolige sider.
-
Du behøver ikke bruge både meta robotter og tag-robots-tag på samme side – at gøre det ville være overflødigt.
fortsæt med at lære
- robotter.,t .t
- Tag-Robots-Tag: en simpel alternativ til robotter .txt og Meta-Tag
- Controlling søgemaskinecrawlere til en Bedre Indeksering og Placeringer
- Robots Meta-Tag og X-Robots-Tag-HTTP-Header Specifikationer
Sætte dine evner til at arbejde
Moz Pro lader dig køre kravler, forskning og rapportere om keyword ranking, og spore dit websted SEO performance, herunder tilgængeligheden, over tid. Prøv det >>